Arm、モバイルAI向けの巨大なIPプラットフォームCSS lumexを提供
IPベンダーのArmは、モバイルAI向けにCPUとGPUとAIアクセラレータを集積できる巨大なIP「arm lumex」を提供すると発表した。同社はこれをCSS(Compute Sub-Systems)プラットフォームのモバイル版と呼び、データセンター向けの「Arm Neoverse」、車載向けの「Arm Zena」に続く、シリーズの一つである。スマートフォンにも巨大なIPでAIワークロードを実行することになる。
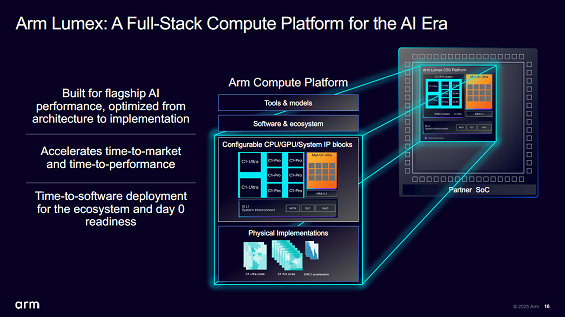
図1 Armが提供するモバイル版Arm CSS lumex 出典:Arm
モバイル版「Arm CSS lumex」の特長は、マルチコアCPUを集めたCPUクラスタに新しいCPUコアC1に「SME(Scalable Matrix Extension)2」と呼ぶAIアクセラレータと共に使うという新しいAI回路である。実績のあるGPUコア「Mali G1-Ultra」はAIアクセラレータというよりは絵を描くグラフィックスプロセッサとして使う。レイトレーシング(Ray Tracing)機能を持たせており、モバイル回路にこの機能を載せたのはこれが初めて。写実的なグラフィックスの動画を楽しむことができるようになる。
Nvidiaのように汎用GPUをAIプロセッサとして使うと、チップ上の積和演算回路が一斉に並列動作するため消費電力が大きくなってしまう。消費電力を増やすことができないモバイルでAIアクセラレータを構成しようとして多数のCPUとAIアクセラレータをセットにしてニューラルネットワーク演算をしているらしい。しかも従来のNPU(ニューラルプロセッシングユニット)でAI演算をせず、CPUクラスタ内にAIアクセラレータ「SME2」を置きそこでAI演算を行う。
CPUクラスタ内にマルチコアCPUと共有メモリがあり、AIアクセラレータSME2コアを導入してAIの演算を行っているという。CPUとSME2とで共有メモリのコヒーレンシー(CPUとアクセラレータが同じデータを共有していること)が担保されているとアームの応用技術部プリンシパルFAEの水上拓也氏は述べている。CPUクラスタ内のC1-Ultraは性能優先のCPUコアで、C1-Proは電力効率優先のCPUコアである。SME2アクセラレータの面積はC1-Proと同程度だとしている。
C1-Ultraの性能は、従来のハイエンド品Arm Cortex-x925と比べで25倍高い。またC1-Proの電力効率は12%高い。これはキャッシュメモリをアップグレードしており、データの移動を可能な限り減らしているからだ。また、SME2アクセラレータを用いたAI性能はこれまでのオンデバイスの5倍と高い。SME2を用いずにCPUだけでAI処理する場合と比べると、SME2アクセラレータを使えば3〜6倍高速になる。
AIのワークロードとして、Armは音声認識を上げている。小声での認識能力は従来の4.7分の1レイテンシが少なく、LLMのGemma3エンコードは4.7倍高速で、オーディオ生成は2.8倍高速だとしている(図2)。
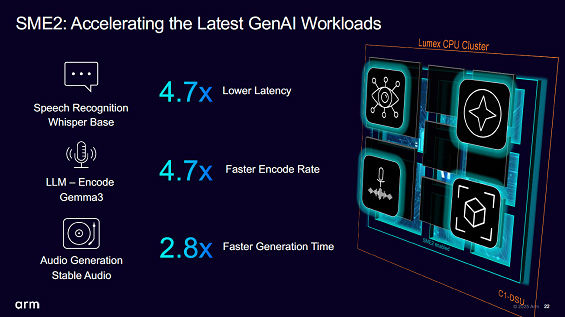
図2 モバイルでは音声認識にAIを使うシーンを想定しているようだ 出典:Arm
グラフィックスコアG1-Ultraの性能は、グラフィックのベンチマークが20%高速、フレーム当たりのエネルギーは9%小さい。また、今回導入されたレイトレーシング性能は、パブリックなベンチマークでは2倍高速に動く。
C1とG1のCPU、GPUの物理的な集積を3nmプロセスで処理できる準備ができているという。Armは、今後下位方向に展開し、PC向けに「Arm Niva」、IoT向けに「Arm Orbis」を次々とリリースしていく予定だ。

