音声で訊ねて音声で答えるエッジ生成AIチップをSiMa.aiが開発
人が話しかければ、言葉で答えてくれる。しかもインターネットにつなぐ必要もない。こんなエッジAIを実現するAIチップをスタートアップのSiMa.ai(シーマドットエイアイ)が開発した。LLM(大規模言語モデル)を使って受け答えだけではなく、映像データも分析する。4000FPS(フレーム/秒)という超高速度映像にも対応する。エッジAIだからこそクルマやドローン、ロボット、監視カメラなどでの広い応用が期待される。

図1 エッジでの生成AIチップとPaletteソフトウエア、実装したドーターボード 新製品チップは「MLSoC Modalix」 出典:SiMa.ai
シリコンバレーを拠点とするSiMa.aiは今月創立7年目を迎え、日本でも半導体商社のマクニカと新光商事もその製品を扱うようになった。新製品「MLSoC Modalix」(図1)は、同社として第2世代のエッジAIチップ。第1世代品「Si MLSoC」はCNN(畳み込みニューラルネットワーク)ベースのディープラーニングチップだが、第2世代品は、CNNに生成AIとなるLLMや映像処理機能も実装したものであり、エッジで音声やテキストでのQ&A、映像解析など機能が充実した。
エッジで生成AIを使えるようになれば、お年寄りや一人暮らしの方がエッジで「おはよう」、「こんにちは、今日はいい天気だね」と言っても、適切な言葉で返してくれる。まさに「相棒」のような存在になる。これまでのスマートスピーカーでは認識できるボキャブラリが少なく、ユーザーには不満が残っていた。エッジ生成AIが可能なこのチップを使ったロボットや人形などのシステムは、全くその心配がなくなる。
新製品「MLSoC Modalix」チップは製造開始しており、そのチップを搭載したSoM(System on Module)とデバイスキットのボードも入手可能になった。このドーターボードはGPUを実装した業界リーダー(Nvidiaと思われる)のボード(たぶんJetson)とピン互換性があり、そのまま差し替えが可能だという。
このエッジAIチップは、テキスト入力のLLMに加え、画像をキャプチャーしそれを解析するため、AIアクセラレータ(図2)だけではなく、ISP(イメージ信号プロセッサ)やコンピュータビジョンプロセッサ、ビデオコーデック、MIPIインターフェイスなども集積している。

図2 新製品「MLSoC Modalix」 出典:SiMa.ai
1チップで映像処理やLLMを含めた処理を行い、結果を音声で出力するための変換機能もある(図3)。画像、映像(ビデオ)、音声処理、音声-テキスト変換、LLM処理、用途別の応用処理機能を経て、テキスト-音声変換機能で出力する。これらの機能を全て集積しているチップは初めてだという。

図3 新製品は画像のキャプチャーからエンコーディング、音声-テキスト変換、LLM、専用ロジック、テキスト-音声変換までの処理を1SoCで行う(緑の部分) 出典:SiMa.ai
映像を解析できる機能を設けたのは、コンピュータビジョン解析での良品・不良品の判定や、銀行の窓口などでのオレオレ詐欺で高齢者が多額の現金を振り込もうとする時を見破るような応用が期待される。NvidiaのエッジAI用の「Jetson」という製品と競合するようだ。Jetsonと比べて1Wあたりの性能は10倍くらい速いという。
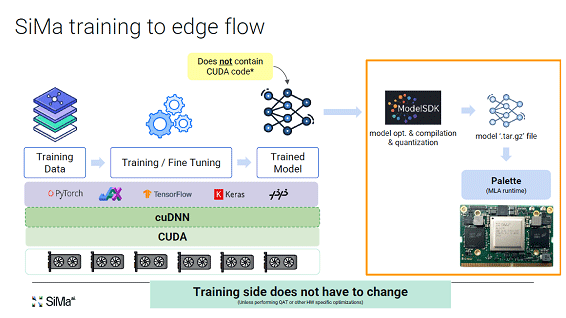
図4 Paletteを使って、学習されたAIモデルをチップに実装する 出典:SiMa.ai
また、このAIチップは、競合するJetsonを意識している。学習されたAIモデルをチップに落とし込むためのSDK(ソフトウエア開発キット)「Palette Edgematic」も開発した。これは学習されたAIモデルをこのAIチップに埋め込み、推論で運用するためのソフトウエア。一般的にはNvidiaなどのGPUと、ベースとなるソフトウエアCUDAを使って、学習させるべきデータをCNNで学習させ、さらに微調整することで学習されたAIモデルを作る(図4)。AIモデルはハギングフェイス(Hugging Face)などに上げられている。ここまではNvidiaの学習作業と同じだが、PaletteではCUDAを使わずに、モデルを最適化、コンパイレーション、量子化した後、トークンのファイルを作りAIチップに埋め込む。
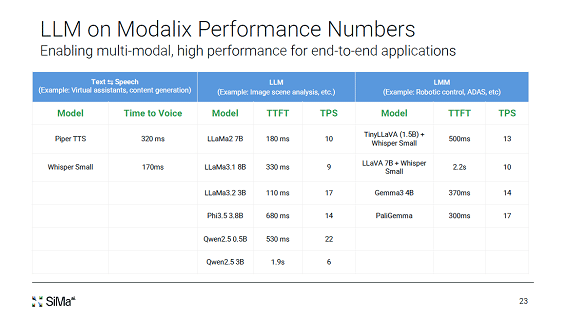
表1 各種のAIモデルを使った性能のベンチマーク 出典:SiMa.ai
SiMa.aiは、Modalixチップの性能をいくつかのモデルで評価している(表1)。テキストから音声への変換では320msあるいは170msくらいで処理できる。また、LLMでは、例えば70億パラメータのLLaMa2 7Bでは最初のトークンまでの時間TTFTは180msかかり、その後は10TPS(Tokens/sec)の速度となっている。AIモデルによってスピードは異なるが、エッジAIとしてならスピードは許容できるのではないだろうか。

