TSMC、Siフォトニクス、ウェーハスケール集積回路の選択肢を提案
AIコンピューティングパワーがけん引し、プロセスノードの微細化は早まっている、とTSMCシニアバイスプレジデント兼副共同最高業務執行責任者のKevin Zhang氏が述べた。これは6月28日に横浜でTSMC Technology Symposium Japanを開催した際、メディア向け技術説明会で述べたもの。

図1 TSMC シニアバイスプレジデント兼副共同最高業務執行責任者のKevin Zhang氏
TSMCは、2nmプロセスノードからA16(1.6nmノード)へのロードマップを示すと同時に、先端パッケージングにも注力する。再配線層のインターポーザーは単なる配線の再構成をするだけではなく、アクティブなチップも埋め込む構造、熱を逃がすサーマルビア、さらにはシリコンフォトニクスにより光導光路を一つのサブストレートに設ける構造(図2)などについても明らかにした。
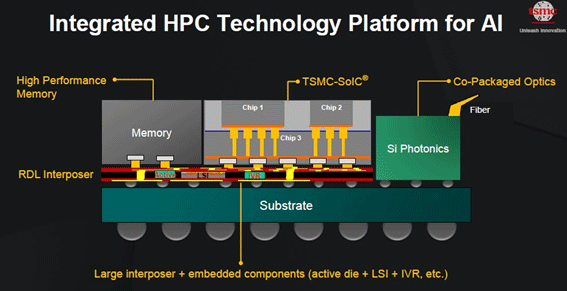
図2 1パッケージ内のI/O回路にSiフォトニクスを導入 出典:TSMC
TSMCはなぜ先端パッケージに力を入れるか。6月はじめのComputex Taipei 2024でNvidiaのCEOであるJensen Huang氏が述べたように、ムーアの法則というよりデナードの法則だが、微細化が行きつくところまで行きついた感があり、微細化のスピードが緩む一方で、生成AIによってAIコンピューティングパワーへの要求が指数関数的に増加してきた。Huang氏は、微細化技術とコンピューティングパワーのギャップがますます広がり、コンピューティングパワーのインフレが起きていると表現した。これを解決する方法は、微細化ではなく先端パッケージ技術であると共に、ウェーハスケールインテグレーションでもある。
TSMCがシリコンフォトニクスに触れたのは、これが初めてと思われる。シリコンフォトニクスはチップ上の入出力関係のみで、チップ内の演算はもちろんシリコンが担う。究極的には1パッケージ内のI/O部分をシリコンフォトニクスで構成し、消費電力とレイテンシを1/10以下にする。
パッケージング技術の他にコンピューティングパワーを上げる手段として、Cerebrasが実用化しているウェーハスケール集積回路技術がある(図3)。Cerebrasは300mmウェーハからシリコンを21.5cm角で四角く切り取った巨大な1チップを設計し(参考資料1、2、3)、TSMCが製造している。最初は12nm、次に7nm、そして今年開発したCS-3は5nmプロセスで製造しており、集積されたトランジスタ数は最初の1兆個から第3世代では4兆個に増えている。ウェーハ1枚でAIコンピュータが可能になる。
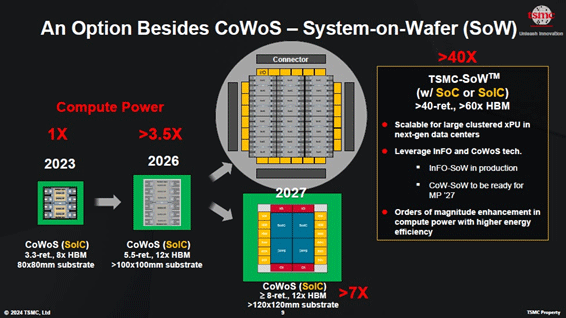
図3 ウェーハスケール集積回路だと、コンピューティングパワーは40倍に 出典:TSMC
TSMCと共同でCerebrasはウェーハスケール集積回路を開発したが、TSMCはこの技術も選択肢(オプション)として掲げている。将来、生成AIを推進する顧客がウェーハスケール集積回路を要求する場合は、PDK(プロセス開発キット)を用意して応えていくつもりか、とKevin氏に質問したところ、Yesと答えた。TSMCは、NvidiaのHuang CEOが述べていた「コンピューティングパワーのインフレ」に応える技術をオプションとしてウェーハスケール集積回路を用意していることで、かつてのウィンテル(MicrosoftとIntel)の関係のように、TSMCとNvidiaの関係が将来ありうることを示唆している。
参考資料
1. 「Cerebras社、ウェーハ規模のAIチップを実装したコンピュータを発売」、セミコンポータル、(2024/07/02)
2. 「7nmプロセスで製造したウェーハ規模の巨大なAIチップ」、セミコンポータル、(2021/04/28)
3. 「Cerebras、4兆トランジスタの第3世代ウェーハスケールAIチップを開発」、セミコンポータル、(2024/03/15)

