7nmプロセスで製造したウェーハ規模の巨大なAIチップ
ウェーハスケールAIチップ開発のCerebras Systemsは、第2世代のウェーハスケールAIチップを開発した。最初のチップが16nmプロセスで製造されていたが、今回は7nmプロセスで作られており、総トランジスタ数は前回の1兆2000億トランジスタに対して2.6兆トランジスタとほぼ2倍になっている。その分チップ上の性能特性も2倍以上になっている。

図1 7nmプロセスで製造したウェーハスケールAIチップ 出典:Cerebras Systems
今回のAIプロセッサWSE-2は、第1世代のウェーハスケールAIプロセッサ(参考資料1、2)と同様、300mmウェーハ1枚から1チップを取るという文字通りウェーハスケールICである。TSMCの7nmプロセスで製造されており、コア数、メモリ容量、メモリ帯域幅、ファブリック帯域幅の特性は全て第1世代のそれの2倍以上となっている。
AIプロセッサを巨大に拡大することによって、例えば演算するのに数カ月もかかるような巨大な学習モデルだと、これまでは研究者が実用的ではないと諦めてきたが、これでも数週間、あるいは数日間で解けるようになる。第1世代のウェースケールチップと比べ2倍の2.6兆トランジスタはこれまでにない最大の半導体チップとなる。現在の最大レベルのAIチップ(GPU)は、NvidiaのA100が集積する542億トランジスタだが、これよりも50倍大きい。その性能は、はるかにA100を凌ぐ(図2)。
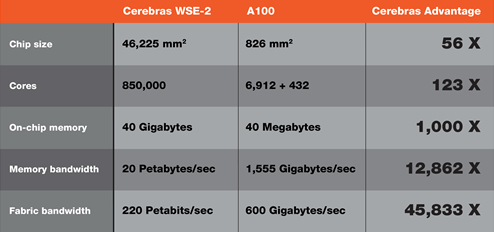
図2 最高性能のGPUチップA100(Nvidia製)と比較 出典:Cerebras Systems
チップが大きい分、演算するコア数や、演算結果を一時的に貯めるメモリが圧倒的に多いため、性能はけた違いに大きい。コア数はA100の123倍、メモリ容量は1000倍、メモリバンド幅は12,862倍、ファブリックバンド幅は45,833倍とけた違いである。チップ面積は4万6225mm2という巨大なシリコンの塊になっている。このため、表面上はステッパのレチクルサイズに合わせた規則的なパターンとなっている。
ウェーハ1枚に1チップというウェーハスケールICは、実は1980年代にもあった。しかしロジックICやメモリICであったため、配線が1本でも切れていると不良品となり、廃棄するしかなかった。このため歩留まりは限りなくゼロに近かった。しかし、ニューラルネットワークで表現されるAIチップだと、配線が1本や2本切れていても学習する能力にさほど差はない。つまり不良品にはならないため、歩留まりはいつも100%なのである。
ニューラルネットワークでは、疎な線形代数演算が必要で、それに合わせた最適で柔軟なコアの設計が求められる。線形代数演算は、行列演算そのものだが、ニューラルネットワーク特有の疎である(Sparse)とは、行列成分の大部分が0(ゼロ)だという意味である。0×数字は0であるから、そういった部分の掛け算は省略することで演算スピードを上げることがAIチップの高速化に重要になる。
ニューラルネットワークでは、演算とメモリを何度となく繰り返す。このため、演算(MAC:積和演算)とメモリをセットにしたアーキテクチャは高速に学習と推論ができる。しかも規模をウェーハサイズに目一杯拡大することでGPUを数十、数百並べるよりも1チップ上で演算・記憶する方が使いやすくシンプルになるという。
これまでの演算では、大きな推論モデルを量子化して小さくすることによって、計算を速めてきた。そうすると、もちろん精度が犠牲になる。このCS-2を使って演算すれば精度を犠牲にすることなく、しかも速度を落とさずに済む。チップ上にある85万コアはオンチップメッシュで接続されており、220P(ペタ)ビット/秒と速い。しかも演算結果を格納するメモリ容量は40G バイトの高速SRAMが配置されており、メモリの帯域幅は20Pバイト/秒と極めて高速である。
同社は半導体チップを設計するだけではなく、これを実装したAIコンピュータCS-2も販売する。チップの冷却やパッケージも自ら設計しており、電源の供給は従来とは違い、各コアに垂直に供給するという。最大のシステム電力は23kWにもなるため、水冷方式を採用している。
チップのソフトウエアプラットフォームには、一般的なTensorFlowやPyTorchなどの機械学習のフレームワークが含まれているため、AIモデルの研究者は使い慣れたツールを使ってCS-2にプログラムできる。
さらに、同社はニューラルネットワークをCS-2の実行ファイルに自動的に変換するコンパイラCGC(Cerbras Graph Compiler)も提供しており、各ニューラルネットワークに固有の配置と配線接続を生成する。この結果、隣接するレイヤー間の通信のレイテンシを小さくできるという。
参考資料
1. ディープラーニング学習にはウェーハ規模の巨大なチップが必要 (2019/08/27)
2. Cerebras社、ウェーハ規模のAIチップを実装したコンピュータを発売 (2019/12/20)

