「ディープラーニング学習にはウェーハ規模の巨大なチップが必要」
かつて、ウェーハスケールLSI(WSI)と呼ばれる巨大なチップがあった。AI時代に入り、ディープラーニングの学習用に1兆2000億トランジスタを集積した巨大なシリコンチップが登場した(参考資料1)。米スタートアップCerebras社が試作したこのチップはWSE(Wafer Scale Engine)と称する21.5cm角の面積のシリコンを300mmウェーハで作製した。
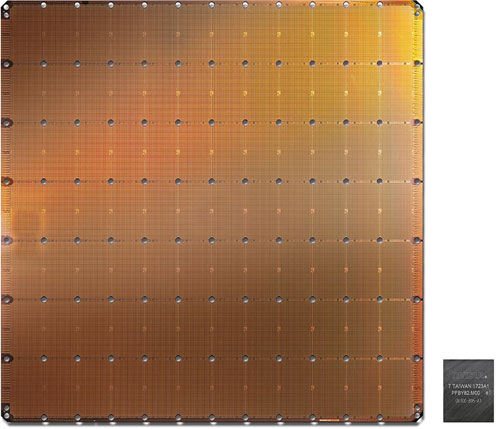
図1 Cerebras社が開発したウェーハスケールの巨大なシリコンチップ 右下のチップはこれまでのNvidiaのGPU 出典:Cerebras社ホームページから
このウェーハ規模のチップの面積は46,225mm2と巨大で、これまで最大のGPU(グラフィックスプロセッサ)が211億トランジスタを集積した815mm2のチップ面積だから、なんとその56.7倍も大きい。300mmウェーハから1枚しか取れないウェーハスケールのAIチップだ。
Cerebras社は、AIチップにとって今がムーアの法則以上にAI演算の需要が3.5ヵ月ごとに2倍に高まる、という新法則の時代を迎えたと見ている。この巨大なAIチップは、TSMCの16nmプロセスで作られており、それでもレチクルサイズを考慮して全体で一つの演算器を作ったのではなく、演算ブロックを12×7個=84個敷き詰めている。一つのブロックの中にAIコアを約4762個集積したようで、AIコア数を40万個集積したと表現している。
AI、特にディープラーニングでなぜ、これほど多くの演算コアが必要なのか。ニューロン1個のモデル(パーセプトロンモデル)は、多入力1出力の演算器(ステップ関数)であり、入力には数十個のデータと、それぞれに重みを掛け、演算器で演算する。図2はアナログ回路で表現したが、デジタル回路でも表現できる。つまり、ΣAi×BiというMAC(積和演算)である。データをAiとすると、重みはBiで表現され、それらを掛け算した結果を演算器に入力する。出力は1か0である。この演算器が並列にずらりと並んでいるのがニューラルネットワークだ。
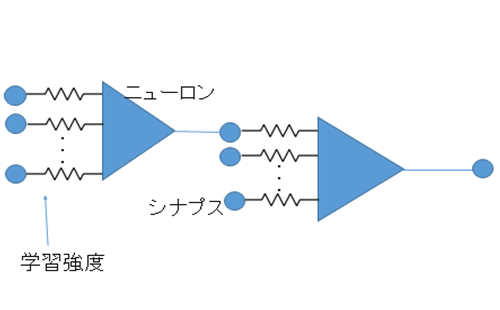
図2 ニューラルネットワークの基本的なニューロンモデル
この演算器を多数並べ、最終的に出力されたデータを次のニューロン(演算器)に入力する。猫を認識する場合には、猫かそうではないかを正解のデータと比較して判断するが、不正解なら逆伝搬といわれるバックプロバゲーション手法を使い、出力側から入力側に戻りながら重みを変えていき、できるだけ猫という正解に近付くまで操作を繰り返す。
各ニューロンに相当する大量の演算器は出力したデータをメモリに保存しておき、次の演算器に入力する時に読み出して積和を再度計算するため、デジタル回路としてはMACとメモリ(DRAM)をそばに置き、一つのニューロンを演算した後、演算結果をメモリに保存し、次のニューロンへそのメモリ内容を入力してまた演算を行う。しかも並列で演算する。このため、MACとメモリを対として持つ構成がAIチップの基本構成となる。この仕組みでは、演算と、その結果を次の演算器に伝える通信経路、が重要な回路要素となる。高速メモリと演算コアは互いにそばに置き、この対をアレイ状に超並列に配置する。
CerebrasのWSEには40万個のAIコアを集積しており、それらは行列成分に0が多い疎行列(sparse matrix)となっているため、SLA(Sparse Linear Algebra疎線形代数)コアが同社のニューラルネットワークの基礎となっている。コアは小さく、キャッシュメモリを含まず、他の関数やオーバーヘッドも含んでいない。ただし、SLAコアはプログラム可能であり、ニューラルネットワークの重みを自由に変えられる。しかも、各コアは制御処理とデータ処理の両方を実行できる。制御処理は並列演算できる座標として使われ、データ処理は演算そのものに使われる。
このチップでは疎行列の掛け算で、0をかける演算が多ければ無駄な演算が増えることになるため、それを省くような処理を行う。ニューラルネットワークでは、データの50~98%がゼロになることが多いが、この場合には掛け算をしない。
CerebrasのWSEは18GBのメモリと9.6PB/sのメモリバンド幅を持つ。いずれもGPUと比べて3000倍、1万倍多いという。レイテンシは1サイクルのみで、全てのモデルパラメータはオンチップに持つ。
このWSEのもう一つの特長は、高速通信ファブリックである。AIチップでは、MAC演算器の数とそのスピード、そしてフレキシビリティが性能を決める。各コアはレイヤー数と共に常に動作しており、高速のバンド幅と低レイテンシで動作させることこそ性能を上げるキモとなる。このためにコアをひと固まりにしてグループにする。一つのブロックにAIコアが約4700個固めて集積しているのはそのためだ。
LSI半導体では、チップ外の通信よりもチップ内の通信の方が数万倍も速い。だからこそ、小さなチップ同士を束にしてまとめ、EthernetやInfiniBand、PCIeなどで通信させて性能を確保する。だから、一つの巨大なチップにした。
Cerebrasは、Swarmと呼ぶ通信ファブリックを開発し、チップ上の大量の配線ネットワークを作り出した。40万個のAIコアはSwarm通信ファブリックで2次元メッシュ状に接続されており、100Pビット/秒という超高速のバンド幅を実現した。Nvidiaも多数の小さなGPUコアを並べ、それらをつなぐ通信配線を工夫している。CerebrasのWSEでもコア間はレイテンシとバンド幅を最適化した短い配線でつなぎ、各演算コアにハードウエア配線エンジンを設けているという。これによって、一つの言葉のメッセージでコアからコア、レイヤーからレイヤーへと通信することができる。しかもコンフィギュアラブルでプログラマブルだとしている。Swarmはハードウエアの配線エンジンをソフトウエアで再構成可能にしており、ユーザー独自のモデルに合うように学習に必要な通信を変えることができるとしている。この結果、一つのハードウエアリンクをメッセージが通る場合のレイテンシは数ナノ秒ですむという。
これだけのWSEであれば消費電力はかなり高いはずだが、Cerebrasは消費電力に関しては何もコメントを出していない。ただ、昔と違って、スーパーコンピュータでは水冷でチップを冷却する手法が定着しており、この巨大なチップも冷却能力の高い水冷を利用するに違いない。
かつてのWSIは結局、商品になりえなかった。歩留まりが良くならなかったためだ。しかも用途がメモリであり、コストを下げられなかった。今回のチップがモノになるかどうかはディープラーニングの学習需要によるが、性能がケタ違いに良くなることだけは確かである。
参考資料
1. Cerebras社のホームページ

