半導体プロセッサメーカーが集結した師走(AI編)
今後が注目される半導体設計企業がこの12月に集結した。Intel、Nvidia、Qualcomm、Arm、そしてRISC-V Foundationだ。脱パソコンを模索するIntelはAI、Nvidiaもゲーム機のGPUからAIへとそれぞれシフトさせ、AIプロセッサIPコアベンダーAImotiveがハンガリーから来日した。前半はAI、後半はIoTを中心に紹介する。
Intel、クラウドからエッジまでAI揃える
Intelは、これまでx86アーキテクチャのXeonプロセッサをAIの演算に利用するスケーラブルプロセッサに加え、企業買収によって3つのAIソフトウエア企業を手に入れた(図1)。Movidius、Nervana、そしてSaffronの3社である。Movidiusは推論に特化したエッジ用のAIチップを設計しており、人間の脳を構成するニューロン(神経細胞)とシナプス(節点)を模倣したニューロモーフィックプロセッサ「Loihi」を、さらにNervana社はニューラルネットワークプロセッサ「Lake Crest」をそれぞれ出してきている。Saffron社の技術は連想メモリを使うAIで、Xeon Scalableプロセッサ上に、金融犯罪を検知するために最適化された「Saffron Anti-Money Laundering Adviser」を載せている。
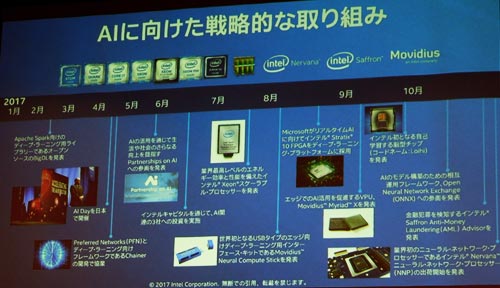
図1 2017年のIntelはAIに力を入れ始めた
IntelはAIをさまざまな分野に向けて用途を想定しており、エッジからデータセンターに至るさまざまなエンドツーエンドのソリューションに対応できるようにしている(図2)。例えば、エッジではMovidiusチップを使ってドローンや監視カメラなどのビジョンプロセッシングを担う。ハイエンドのデータセンターでは、Nervanaニューラルネットワークプロセッサで膨大なデータのバッチ処理を行う。特に力を入れるNervanaでは、SDK(ソフトウエア開発キット)やライブラリを揃え、さらにAIフレームワークであるCaffe 2やTensorFlowなどをサポートする。
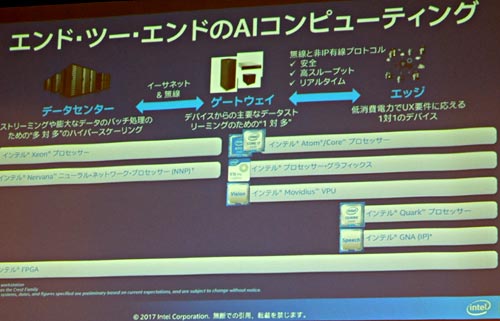
図2 エッジからデータセンターまでのチップを揃えるIntel
Intelの強みは何といってもAltera買収によってFPGAを手に入れたこと。特にデータセンターなどでは、並列処理に優れたGPUとはいっても、さすがにハードウエア回路であるFPGAには性能面で及ばない。FPGAのStratix 10と、強力なCPUであるXeon、そしてNervanaのニューラルネットワークプロセッサと3つを使うことができる。現在最強のXeon Platinum 8180プロセッサとIntelのMKL(Math Kernel Library)を使い、最適化されたCaffe AlexNetで前世代のプロセッサで比べると学習のスループットは113倍、推論ではCaffe GoogleNet v1で138倍上がったとしている。
Nvidia、AI向けGPUで性能を優先
一方、AIで最近もてはやされているグラフィックスプロセッサチップ(GPU)のNvidiaは、AIに向いたGPUシリーズのCUDAを発表して以来、進化を遂げている。2012年の「Kepler」から数えて第4世代に相当する「Volta」アーキテクチャでは、「Tesla V100」という製品があるが(図3)、これは最大125TFLOPSの半精度(16ビット)性能を実現するTensorコアを搭載しているという。このチップを搭載したAIスーパーコンピュータともいうべきDGX DGX Stationは、1Peta FLOPSという超高性能なコンピュータである。

図3 AIに適したGPUのCUDAの進化 最新チップはVoltaシリーズのTesla V100
このTesla V100製品の威力をデータセンターレベルで比較すると、4万5000枚の画像を1秒間で識別するのに必要なデータセンターのサーバー数は、従来のCPUサーバーだと160台必要で、消費電力は65kWだったが、Tesla V100を搭載したGPUサーバーだと、8台で済み、消費電力は3kWで済んだとしている。つまり、画像認識に40倍高速になり、自然言語翻訳処理をさせる場合には140倍高速だったとしている。
NvidiaのCEOであるJensen Huang氏(図4)は、1台のTesla V100サーバーが約50万ドルを節約したことに相当する、と述べている。同氏は再帰型ニューラルネットワーク(RNN)を使って作曲のデモも見せた。バッハ、モーツアルト、ベートーベンの音楽と、「スターウォーズ」や「インディ・ジョーンズ」、「ハリー・ポッター」など映画音楽の巨匠ジョン・ウィリアムズの作品を学習させた後、作曲させたシンフォニー音楽をビデオで流した。

図4 NvidiaのCEOであるJensun Huang氏
AIはクルマの自動認識に使う技術でもあるが、これからの自律運転にはソフトウエアがカギになろうと述べ、コネクテッドカーでのSOTA(Software on the air)などを含め、クルマは、「Software-Defined Car」になると述べた。これはスマートフォンがアプリでさまざまな機能を追加できるようになったことがクルマにも起きるだろうとした。
AIのIPベンダーも登場
ハンガリーのIPベンダー、AImotive社がエッジ向けの推論専用のAIプロセッサコアのライセンス提供を国内で始めた。標準化団体のKhronos Groupが定めたNNEF(Neural Network Exchange Format)に準拠したニューラルネットワークのアクセラレータIPである。現行のGPUと比べて電力効率が4~5倍高く、MAC(積和演算器)の使用率が94%と高い、としている。
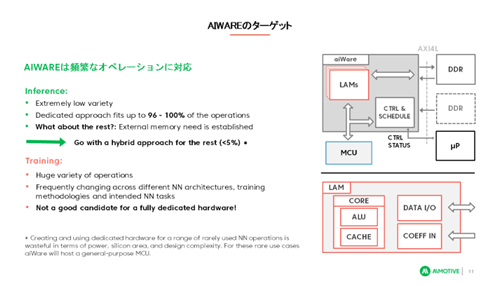
図5 マイコンと一緒に動くAIアクセラレータ 出典:AImotive
同社は、開発をサポートする日本の半導体専門商社、菱洋エレクトロを通じて販売ライセンスをサポートする。このIPはマイコンと共に動作するアクセラレータであり、スケーラブルな演算器であるLAM(Layer Access Module)が外付けメモリ(DDR)とやり取りする(図5)。国内でもグラフィック系のIPベンダーであるDMP(デジタルメディアプロフェッショナル)がAI推論用IPをライセンス販売している。次回は、IoTとセキュリティの最新の動きを紹介する。

