ニューロチップ概説 〜いよいよ半導体の出番(4-2)
ニューロチップの代表例として、(4-2)ではDNN(ディープニューラルネットワーク)の開発2例を紹介する。中国科学院のDaDianNaoチップと、韓国KAISTのDL/DI(Deep Learning/Deep Inference)チップを紹介している。(セミコンポータル編集室)
著者:元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
4.2 代表的チップ(DNN用チップ)〜DRAM混載もしくは学習機能
本節では、狭義のDNN(非CNN)用のチップの説明をする。全結合層主体の構成を念頭に、学習機能を兼ね備えたチップである。しかし回路構成まで詳しく記述した例は少ない。本章ではCAS(中国科学院)のDaDianNaoとKAISTのDL/DI(Deep Learning/Deep Inference)の2チップを説明する。前者は2014年12月のMicro47で、後者は2015年2月のISSCC2015で発表された。共にフルペーパーの論文(参考資料37, 86)が出された。
DaDianNaoは、拡張性を持つオールマイティーなスーパーチップである。Dl/DIはDBNのネットワークモデルに畳込み層の要素を入れたものでいわゆるCDBN(Convolutional Deep Brief Network)対応のチップである。すなわちRBMによる学習を取り入れた本格的な専用チップである点に注目して欲しい。なお、全結合のモデルであるRNNとRL(Reinforcement Learning:強化学習)に関しては割愛した。
(1)DaDianNao (CAS) 〜 A Machine-Learning Supercomputer
このチップは、2014年末のMicro47(The 47th International Symposium on Microarchitecture)でBest Paper Awardを受賞したチップ(CAD実装まで)である(参考資料37)。タイトルに”A Machine-Learning Supercomputer”と付けられているように従来のGPUの性能を速度で50〜100倍、エネルギー効率で1000倍程度改善したものであった。1年半以上経つが、ワンチップとして実質の速度で、5.6 TOPS (Tera Operations Per Second)の性能を誇っている(後述するEIEが、圧縮技術を用い実効性能でDaDianNaoを上回っている:表6)。共同著者の仏Inria(フランス国立情報学自動制御研究所)の技術者をリーダとして招き開発を推進した。2014年末の当時も現在も学習の時間をいかに短縮(演算の高速化)するかが喫緊の課題であったことから、(AlexNetの学習の例もあるが、当時は何であれ学習に1週間はかかると言われていた)アルゴリズムの研究者やアプリケーションサイドの方との会話でよく話題に上り、かつ期待の大きかったチップであった。
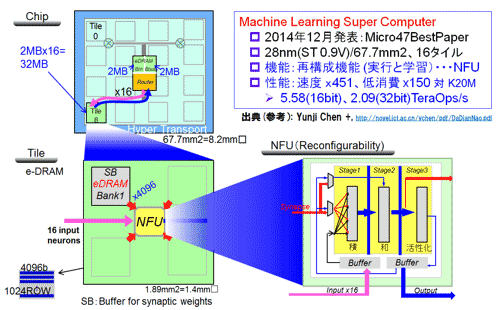
図31 DaDianNao(CAS)の概要仕様 (参考資料37を参考に作成)
(ア)チップ構成
論文は、CNN/DNNなりAlexNet等ネットワークモデルの知識がないと読みづらいが、LSIもしくはDRAM混載チップとしてみるならば内容は単純だ。メモリの格納は、外から入ってくる入力・出力バッファ用、および重み(シナプス値)の格納はDRAM混載で、そして中間データの一時格納はSRAMで行っている。図31の左上の図が配置だ。32MBを重みに、入出力バッファ用に4MBを割り振った。前者はタイル状の16ヵ所に配置され、後者は中心に配置された。周辺四方にHyper Transportの通信用インターフェースを配置した。ファウンダリとしてSTMicroelectronicsの28nmプロセスを想定している。チップサイズは、8.2mm角だ。
チップの中心のバッファとタイルとは、太ったトポロジー(Fat Tree構成(16ビット))で通信を行っている。その一つのタイル(Tile:左下)は、4個のeDRAMのバンクに分かれる。バンド幅は4,096ビット/バンクとかなり大きい。タイルの中心にNFU(Neural Function Unit)を有する。バンクから重み(シナプス値)を読み込み、左から入る入力データとで演算処理をNFUが行う。右下にNFU内部構成を示した。ピンク線が入力データ(入力特徴マップもしくは入力イメージ)、青線が出力データ(出力特徴マップ)を、さらに赤線が重み(シナプス値)の流れを示す。
(イ)NFU (Neural Function Unit)
16入力(16ニューロン)および16出力(16ニューロン)が同時に扱える。赤い矢印は、シナプス値(重み)の読み込みパスである。各ブロックは、積、和、正規化関数/活性化関数処理(Transfer関数)、出力、中間値バイパス処理(そのために前述したように8KBのSRAMを内蔵)を受け持つ。
16x16=256シナプス(重み)がアクセス可能である。256個のMAC処理が並行で同時に行える。256 MAC×2 ×16Tile×0.606 GHz = 5.0 TOPSの処理能力を有する(実際はもう32 MAC分演算が可能で5.6 TOPS)。学習時にはセレクタで情報のパスを再構成しフェーズの変更に対応する。フィードバック値(gradient)を入力するパス、また微調整後のシナプス値(Updated Synapse)をe-DRAMに格納するパスを再構成する。
(ウ)コンフィギュラビリティ (再構成)
図32に層、およびフェーズ(学習と実行)の切り替えの流れを示した。論文を参考に多少推測を入れて作成した。図31の右下図のNFU(Neuron Function Unit)のパイプラインのステージ(Stage 1/2/3)を切り替えることにより、畳込み層/全結合層/プーリング層/正規化関数あるいは活性化関数の各処理を再構成する。もちろん、シナプスの入力の有無も関連する。プーリング層ならシナプスの入力は不要だ。ネットワークの処理が進み、層が変わる(例えば畳込み層からプーリング層)タイミングでダイナミックに切り替える。また実行モードから学習モードも同様に切り替えるが、前述したシナプスのアップデートのパスも構築する必要がある。順伝播(Forward Propagation)と逆伝播(Backward Propagation)の切替えにより学習を行う制約ボルツマンマシン(RBM:Restricted Boltzmann Machine)の手法を用いた学習の記述が有り適用している模様だ(詳細の説明はない)。
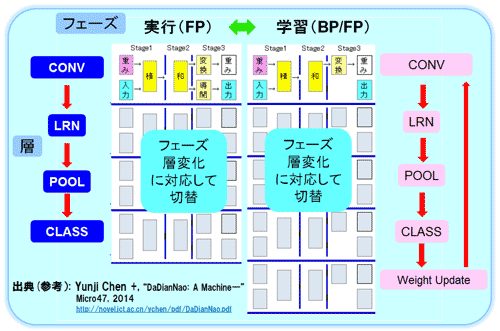
図32 再構成の切り替えの流れの概略図 (参考資料37を参考に作成)
(エ)結果:性能
消費電力:図33にシミュレーションによる消費電力の分布を示した。チップ全体で16Wと試算されている。そのうちチップ間通信を行う高性能伝送回路(HT:Hyper Transport、Point to Point式の汎用接続技術)の消費電力が半分を占めた。著者らも述べているが今後工夫が必要な箇所だ。なお、本チップはサーバ用なので、多チップでの展開を視野に入れることが必須だ。敢えて単体での使用を念頭に置くと(例えばエッジ系応用)、全体としては10W位の消費電力とみなせ、内部RAMアクセスに6Wを要している。内蔵とはいえ、DRAMでは消費電力がやはり大きい。
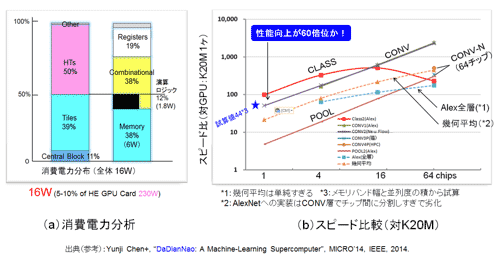
図33 DaDianNaoの消費電力分析とスケーラビリティ比較 (参考資料37を参考に作成)
出典元:STARCの調査報告書より転載
スピード:図33に論文のデータを参考に作成したスピードのデータを示した。縦軸はNVIDIAのGPU K20Mとの相対スピード比だ。横軸は並列動作させた数(スケーラビリティー)だ。チップを増やす毎に性能がスケールアップするか(直線が望ましい)を判断できる。いくつもの線があるが、畳込み層(CONV層)、プーリング層(Pool層)等のスケーリング性能を示した。全体に1チップで10〜100倍の高速性を示している。スピードCONV層とCLASS層(全結合層)で決まることからその中間値とみて、ワンチップの場合には60倍程度の改善が見られる。
GPU K20Mの仕様データとDaDianNaoの回路構成からスピード性能比較を簡単に試算した。メモリバンド幅とMACの数を単純に掛けたもので比較すると、DaDianNaoは44倍の性能が単体(ワンチップ)で出ることがわかる。DaDianNaoとK20Mとの具体的な数値を示すと、バンド幅が5TB/s対、208GB/sで24倍、MAC数が9k個対5k個で1.8倍となり、両方を掛け合わせると約44倍だ。評価値とほとんど変わらない。
ポイントはスケーラビリティだがCONV層はほぼ直線だ(若干落ちるのは入力マップの周辺の処理の影響が出る)。重要なのは全結合のCLASS層だが、さすがのDaDianNaoでも16チップ以上で性能が劣化している。CONV層だと独立しているので分配による悪影響は小さい。とはいえ、CONV層とCLASS層の平均で見ると16チップから64チップの間位まではスケーラビリティがあり、その比率は800倍程度の高速化が見込める(対K20Mひとつとの比較である点注意が必要だが、当然GPUのスケーラビリティは極めて低いはずだ)。
他チップとの比較:Eyrissとの比較をする。表6で、面積効率(GOPS/mm2)とデザインルールと周波数を並べると、DaDianNao (82.7 GOPS/mm2, 28nm, 606MHz) vs Eyriss (6.23 GOPS/mm2, 65nm, 200MHz)となる。EyrissをDaDianNao並みにすると、102 GOPS/mm2となる。IoEでも同様である。Eyeriss/IoEが畳込み層用のチップであることから、DaDianNao/DRAM混載がメモリアクセス律速の全結合もしくは学習用のチップとして初めて特徴が出ることを改めて認識できる。
(2)DL/DI (Deep Learning/Deep Inference) (KAIST)〜DBNを本格実装
2015年のISSCCで韓国KAISTより発表された(参考資料86)。教師無し学習が可能なチップだ。DaDianNaoと異なり学習と実行の各々の回路を持つ。DL/DIの呼称は筆者が論文のタイトルより取った。DaDianNaoがサーバを主ターゲットとしたのに対し、DL/DIはフロントエンド(エッジ)もしくはニアエンド(フォグサイト)をターゲットとしている。発表ではクラウド側のデータ格納/通信の負担削減のためにニアエンドに学習機能を持たせる点に重きをおいて講演を行っているが、ほぼ1年後のフルペーパーでは、モバイルでの学習機能搭載までターゲットを広げて論文を構成している。0.2W程度で、エネルギー効率は1.93 TOPSとかなり高いことから適用範囲は広い。
(ア)学習機能・・・教師無し学習
図34に論文を参考に作成したチップのブロック構成を示した。実行エンジン(Deep Inference Engine)と、学習エンジン(Deep Learning Engine)、さらにはグローバルな乱数発生回路:TRNG (True Random Number Generator) の3つの構成からなる。学習エンジンは4つのコア(DLコア)からなる。詳細な説明は割愛するが、4つのステージからなるパイプライン構成となっている。かつポジティブとネガティブの二重スレッド方式を採用している。DBN (Deep Neural Network:参考資料78, 80) におけるRBM (Restricted Boltzmann Machine 76,77) でのNegative/Positive方向の学習手順を効率よく実現すべく構成されているとみている。
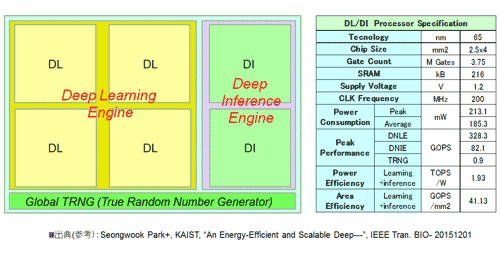
図34 DL/DIの概要仕様 (参考文献86を参考に作成)
(イ)乱数発生器およびその供給システム(ネットワーク)
図34に示したように、学習(DL)および実行(DI)に必要な乱数発生器は演算エンジンに対して、個々に持つ方式ではなく面積効率の良いグローバル(Global)な方式を採用(図のTRNG)した点が全体アーキテクチャの大きなポイントであると彼らは主張した。データが密集することを防ぐために、乱数の配信と学習/実行のデータ送信のパスを完全に独立させるアーキテクチャがその内容だ。
(ウ)結果:性能
彼らはCDBN (Convolutional Deep Brief Network:参考資料80)ネットモデルでの教師無し学習を32×32 RGB 手形状の認識に適用した。LSIとしての性能を図34の表に示した。学習でのピーク性能は328.3 GOPSとかなり高い。その結果として1.93 TOPS/Wというこれも高いエネルギー効率値を叩き出している。比較をする報告がほかに多くないこと、また論文で性能に関して紙面を多く割いていないことから1.93 TOPS/Wの良し悪しを判断するのは難しいが、かなりの性能には見える。なお、実行(DI:Deep Inference)では3.1節で述べた並列処理に加えて、タスクレベル、層(Layer)レベルでの並列処理を加えて高速化した。
編集注)百瀬氏の現在の肩書は、北海道大学 大学院情報科学研究科 学術研究員である。

