インテルの22nmFINFETプロセスをファウンドリとして使うTabula社
インテル社の22nm、FINFETプロセスをファウンドリとして利用する契約を、新興FPGAメーカーのタブラ(Tabula)社が締結した。タブラ社は、ロジックを時分割にリコンフィギュア(再構成)することで、これまでのハイエンドFPGAよりも小さな面積でFPGAを実現できる3D Space Timeアーキテクチャを特長としてきたベンチャーだ。

図1 Tabula社マーケティング担当のAlain Bismuth氏
プログラマブルデバイスでありフレキシブルな半導体チップであるFPGAの泣き所は、論理ゲート数の割合には配線領域部分が大きすぎてチップ面積が大きくなってしまうこと。FPGAはチップ面積を小さくするため微細化技術の先頭を行くが、コストが高くなってしまうのはやむをえない。タブラ社のマーケティング担当バイスプレジデントのAlain Bismuth氏は、「配線領域部分がスピードのボトルネックにもなってしまう」と言う。
ダイナミックに時分割でロジックを再構成していくタブラのアーキテクチャは、同じデザインルールでは2大メーカーのFPGAよりも優れている。にもかかわらずなぜ22nmへと微細化が必要なのか。Bismuth氏はユーザーからのデータレートの高速化の要求は果てしなく続くからだとしている。特に、通信キャリヤの基地局では100Gbps/400Gbpsといった高速化を期待している。スマホなどの普及によって通信トラフィックが膨大になることに対処するためだ。データレートは高速であればあるほどよいという状況だ。つい先日もNTTドコモやKDDIの携帯やスマホがつながらない、といったクレームが殺到したが、通信トラフィックが急増してきたからだ。
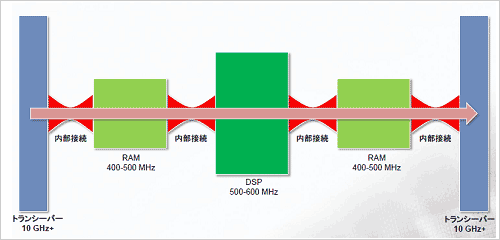
図2 FPGAのボトルネックは配線 出典:Tabula社
タブラ社に来る前はアルテラ社にいたBismuth氏によると、FPGAの配線領域がスピードのボトルネックになっている。例えば10Gbpsのトランシーバファブリックでは、FPGA内部のRAMやDSPに相当する回路ブロックを設けてもそれらをつなぐ配線部分がネックになってスピードが出ない。これを解消するのが3D Spacetimeアーキテクチャであり、内部接続2GHzでボトルネックが解消され、そのまま通信できるとする。これはチップを時分割でダイナミックに再構成するため、チップそのものの配線領域が少なくてすむから高速性が維持されるとしている。
このアーキテクチャはダイナミックに再構成するための制御回路がキモとなる。この回路にはフェッチなどのためにRAMを多く用いるため、制御回路をチップ内に構成する。メモリとのやり取りが頻繁になるため、この制御回路を別チップにはしない。
タブラの狙いはまずはハイエンドの通信インフラの高速化である。従来のFPGAを超える性能を出せるアーキテクチャだからこそ、超ハイエンドの応用にフォーカスしていく。このためには微細化もその手段の一つ。32nmの従来型プレーナMOSトランジスタと22nmの3次元FINFETを比較すると、電源電圧1Vで18%高速に、0.7Vだと37%も高速になるという。タブラのSpacetimeアーキテクチャと22nmのFINFETこそ、数100Gbpsの通信を可能にするデバイスだとBismuth氏は言う。

