SPIフォーラム「3次元実装への道」が示した3D-ICの現実解
セミコンポータル主催のSPIフォーラム「3次元実装への道」が3月25日、開催された(図1)。高集積化の手段をこれまでの微細化だけではなく、縦に積み上げる方式も加わると見て、企画した。システムから見た3D、ブームになりそうなFO-WLP、実際にメモリシステムを構成するHMC、など現実解は着実に進んでいる。

図1 SPIフォーラム「3次元実装への道」講演風景
最初の講演は「システムアーキテクトから見た3D-IC」と題して、トプスシステムズの代表取締役であり、JEITAの3次元集積回路サブコミッティ委員でもある松本祐教氏から、アプリケーションと制約条件の変化でアーキテクチャが大きく変わる、という話から始まった。2000年代に入り、消費電力の制約からマルチコア、メニーコアへと並列処理に進み、LSIも積層化が進むことは自然だとした。
組み込みシステムのコンピュータはさらなる性能も求められる。例えば、クルマの画像認識・音声認識には1TOPS(Tera Operations per Second)以上の性能が求められるという。しかもスケーラビリティが重要で、コア数を増やしても簡単に設計できる手法が重要だ。またCPUの性能を上げるうえで、CPUとメモリとのかい離が進んでいる。例えば、CPUの性能は毎年60%ずつ上がっているのにもかかわらず、メモリの性能は毎年7%しか増えていない。そこで、CPUの性能を上げるために並列性を多用する。命令の同時発行というような並列化を行う。一方、MOSトランジスタは微細化と共に、稼働しないトランジスタ数が増える傾向がある。このため、マルチコアやメニーコアで同時に動かすトランジスタ数を増やし、周波数を上げずにクロック当たりの演算数を上げる。
それでも性能をさらに上げる場合にはやはりICチップを積層することになる。ただし、歩留まりよく、しかも簡単にいろいろなチップをつなげるようにするためには、3D-ICの接続を共通化し、3Dにはチップを取り換えるだけで済むようにすることが重要という。
その前にFO-WLPが先行
3D-ICに進む前に、スマートフォンのようなモバイルデバイスでは、FO-WLP(Fan-Out Wafer Level Packaging)が今後発展しそうだ。昨年末に開催されたISSM 2014の基調講演で、TSMCのR&D Design and Technology Platform部門のVPであるCliff Hou氏は、「3D-ICはまだ先だが、InFO(Integrated Fan-Out)パッケージは2015年にスタートする」と述べていた。TSMCのInFOと同様なコンセプトが東芝の明島周三氏が講演したFO-WLPである(図2)。
図2 FO-WLPはフリップチップを置き換える可能性を秘めている 出典:東芝
明島氏は、FO-WLPはまずモバイル製品に使われるだろうと見ており、その理由を、CPUとアナログ/RFを1チップにしにくいからだとする。アナログ/RFは微細化しにくいため、デジタルのCPUとの1チップ化は難しいとする。CPUは、28nmから14/16nmへと微細化が進む一方で、アナログ/RFは90nmと微細化を進めるほどではないからだ。モバイルにはCPUとRF/アナログが欠かせない。2チップを搭載するためには従来のフリップチップなどではインターポーザの配線層数が増えてしまうが、FO-WLPだと1層で済むと明島氏は言う。
3D-ICの標準化作業も進展
続いて、元ルネサスエレクトロニクスで現在、産業技術総合研究所の島本晴夫氏はSEMIのパッケージ標準化委員会のメンバーとして、3D-ICの標準化策定作業について述べた。TSVの用語の定義から始まり、TSVの反りや曲りなどの計測技術やアラインメントマスクの位置などがある程度規格が決定しており、ウェーハスタックの同定やマーク、品質試験、ガラスインターポーザの規格などについては審議中だとしている。例えば、重ね合わせたチップの曲げ試験に関しては、カンチレバーのようにチップを置き、固い曲げツールで割れるまで力を加えるテストを提案している。
午後からは、現在、エレクトロニクス実装学会名誉顧問の傳田精一氏が、3D-ICのオーバービューを行った。3D-ICならではのメリットは、やはりメモリとプロセッサの距離を短くし、しかもWide I/Oのようにアクセスビット数を512ビットや1024ビットに増やし並列度を上げて処理速度を稼ぐ応用に向いていると述べた。Gbps当たりの消費電力、すなわち電力効率がPoPのLPDDR3よりも2.5Dのインターポーザを使う方がより低く、さらに3DのTSVはさらに数分の一に減ることを示した。Wide I/Oよりもさらに並列度の高いHBM方式、HMC方式についても触れている。また、インターポーザを使わずにプリント基板上の微細配線を利用して、TSVチップと他のチップを並列に並べて配置する2.1Dについても述べている。
接続の物理検証と性能確認のシミュレーション
メンターグラフィックスジャパンの丁子和之氏は、インターポーザを利用してチップを並列に並べる2.5D方式は、従来の設計技術を使えることから、比較的長く続くのではないかと見る。ただし、3D-ICへの準備も怠らない。TSVによるスタックICでは、スタックする前に各設計データファイル(GDS-II)をつなぎ合わせて物理的な検証を行い、動作を確認する。そのためのツールがCalibreである。
Calibre 3DSTACK検証ツールでは、各チップの接続情報の検証だけではなく、動作タイミングが期待通り得られるかどうかの検証も行う。例えばマイクロバンプが一部だけ接続していても不良ではないが、位置ずれによる寄生容量の増加などでタイミングが遅れたり、TSVの形状によって寄生インダクタンスを生じたりすることでノイズ源になったり、これまで問題になっていなかったことが問題になることがある。Calibreはそれを検証する(図3)。加えて、熱の問題も出てくるため、熱がどのように逃げるかをシミュレーションするFloTHERMも使って熱分布を見積もる。
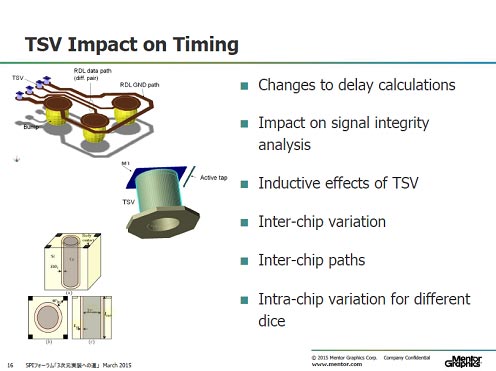
図3 TSVのサイズや位置のズレがタイミングに影響 出典:Mentor Graphics
アンドールシステムサポートの谷口正純氏は、BGAパッケージやハンダボールを使ったパッケージ端子が基板やインターポーザと接続されているかどうかがわからない、という問題を解決する手段について述べた。3D-ICや基板内蔵ICなどの接続は、X線を使っても接続されているかどうかの確認観察ができない。そこで、JTAG(バウンダリスキャン)と呼ばれるテスト法で接続を電気的にチェックする方法を紹介した。これは、LSI内部のパッド近くにバウンダリスキャンセルと制御回路を集積しておく必要があるが、接続情報はセルをシリーズにスキャンすることで判断できる。
JTAGそのものはすでに標準化されているが、これまではあまり使われてこなかった。しかし、BGAの普及と共に接続情報をチェックしたり、クレームなどで戻ってきたチップの故障解析をしたりするのに普及してきたという。
パッケージングの生産性を上げる
OSATを代表して、ジェイデバイスの勝又章夫氏は、パッケージの生産効率を上げるためPLP (Panel Level Package)基板をベースにした技術を紹介した。これは、ダイシングした個別のチップをマウント、ボンディングするのではなく、50cm四方の大きな基板の上の多くのチップをリフロー実装するもの。その大きさ(面積)は300mmウェーハの3倍もある。
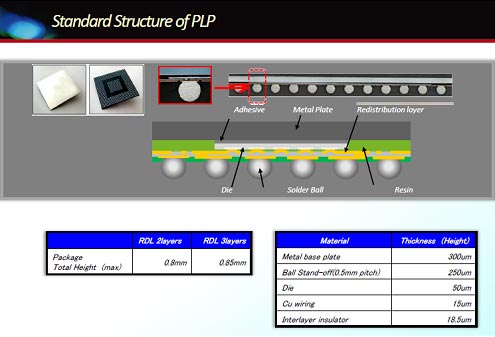
図4 チップの実装基板を515mm×410mmのパネルでバッチ処理 出典:ジェイデバイス
その断面は図4のように、再配線されたプリント基板内にチップを埋め込み実装し、さらに上にメタルプレートを被せたパネルサイズの基板から、パッケージサイズ5mm角のICだと6752個、10mm角のICでは1652個、それぞれ一括でパッケージングできる。
面積・消費電力の効率は抜群のHMC
最後に、マイクロンジャパンの朝倉善智氏は、TSVを利用して積み重ねたDRAMメモリアレイチップを構成するHMC(Hybrid Memory Cube)について紹介した。プロセッサとこのメモリを2.5Dや2.1Dのように配置し、プロセッサの性能を上げる。HMCは、市販のDRAMをスタックしたものではなく、8個のDRAMメモリアレイをスタックしている。一つのチップのメモリアレイを16分割しており、分割された領域をボールト(Vault)と呼び、メモリのボールトを縦に8枚分串刺しにしている。メモリはボールトごとにアクセスする。メモリキューブには16個のボールト領域があり、それぞれは独立している(図5)。
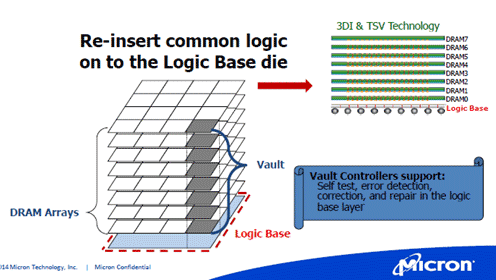
図5 HMCのコンセプト 出典:Micron Technology
8枚のメモリを制御するのは最下層のロジックである。ここでは、BST(Built-in Self-Test)、誤り検出・訂正、ボールト内でのリペアなどを行う。さらに、このロジックチップには、メモリとプロセッサリンクとをつなぐリンクインタフェース制御回路があり、プロセッサと通信する。
今回の第2世代のHMCでは、4本のリンクを備え、それぞれのリンクごとに受けと送りでそれぞれ最大16レーンを持つ。各レーンは10Gbpsで動くため、1レーン全体では320Gbps =40GB/sとなり、全部で4レーンあるため160GB/sとなる。HMC最大のメリットはボードスペースが従来のDRAMと比べ1/10に減り、消費電力も大きく減少すること。例えばDDR3で構成すると2.25kWだったのが、HMCでは330Wに減った。
HMCは、ハイエンドのHPC(High Performance Computing)や通信ネットワークの基地局、データセンターのサーバーなど、プロセッサの速度を競うハイエンド分野で使われるだろう。

