ニューロチップ概説 〜いよいよ半導体の出番(2-1)
第2章:ディープ・ニューラルネットワークのニューロチップへの実装〜その勘所は!!
この第2章は、人工知能(AI)の代表的な応用である画像認識によく使われているCNN (Convolutional Neural Network:: 畳み込みニューラルネットワーク)を紹介し、LSI化する場合に必要な演算を軽くするためのテクノロジーを中心に解説している。第2章は3部に分けて掲載する。最初となる2-1は、CNNの基本構成を紹介している。(セミコンポータル編集室)
著者:元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
第1章の冒頭で予告した内容を変更し、第2章では教師有り学習で画像認識の代表的ネットワークであるCNN (Convolutional Neural Network:畳込みニューラルネットワーク)を用いて、ディープ・ニューラルネットワークをLSIに実装した際に重要となる各種の勘所を説明する。CNNが最もなじみ深く、世に多くの実績を上げているからである。
最初に、2.1〜2.3節でCNNの基本を説明し、そしてディープ・ニューラルネットワークのアルゴリズム・モデルの全体の動向を概説する。中盤の2.4〜2.6節では、CNNの代表的な幾つかのモデルのアーキテクチャ、構成要素、演算数とパラメータ数をその推移と共に説明する。最後に2.7、2.8節で、最新の低ビット化・圧縮技術を紹介し、最新のディープ・ニューラルネット(ex. CNN、ResNet 34層)がモバイルに搭載可能(サブ0.1W級)であることを簡単な試算を用いて示す。
第2章:ディープ・ニューラルネットワークのニューロチップへの実装 〜その勘所は!!〜
2.1 CNN基本構成(1)〜演算ブロック〜
2.2 CNN基本構成(2)〜ネットワークとパラメータ 〜
2.3 ディープ・ニューラルネットワーク全景〜アルゴリズム・モデル〜
2.4 CNNのモデルの進化(1)〜アーキテクチャの変遷:より広く?! より深く152層〜
2.5 CNNのモデルの進化(2)〜構成要素の勘所:ポイントは5、6カ所〜
2.6 CNNのモデルの進化(3)〜演算数とパラメータ数:34層位で良いのではないか?!〜
2.7 ディープ・ニューラルネットワーク(1)〜メモリ実装に関する考察:3つのタイプ〜
2.8 ディープ・ニューラルネットワーク(2)〜メモリ量激減 サブ0.1Wも!モバイルにロックオン
2.1 CNN基本構成(1)〜演算ブロック〜
図6にCNNの基本的な演算ブロックである層と関数だけで構成した画像認識(一般物体認識)用ネットワークの簡略図を示す。CNNを通して対象物(ひまわり、チューリップ、・・・、猫等々)を分類(多クラス分け)する。左側から「ひまわり」の画像(通常3枚 RGB)を入力として入れる。図の下段は入出力のフレーム(外枠)を、上段はそのフレームの内容であるデータイメージの流れを示す。図の説明を前段部の特徴抽出部と後段部の分類器に分け説明する。なお、この作業は認識という実行フェーズである。今回は詳しく説明しないが、それ以前に学習という作業が行われその確定したネットワークに画像を入力する。
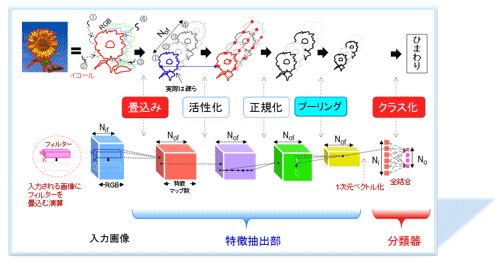
図6 CNNの構成概略
(1) 特徴抽出部
前段の特徴抽出部は、2つの層(畳込み層・プーリング層)、および2つの関数(活性化関数・正規化関数)からなる。各層と関数に関して説明する(詳細は参考資料8、6参照)。
畳込み層
畳込み層に関しては半導体で画像のフィルタ処理に同様の処理が使われているので馴染み深い方も多いはずである。直感的には入力画像を、例えば斜めのフィルタなり格子状フィルタ(参考資料6の102頁に実際のフィルタ例)なり、フィルタ越しに見た入力画像の結果を出力側に転写する作業とイメージすると理解しやすい(実際のフィルタはかなり小さいサイズ3x3大きくても11x11であるが)。同じく「畳込み」のネーミングに関しては図6の下段の一番左側に挿入した挿絵の様に「入力される画像にフィルタを畳み込む演算(参考資料14)」と捉えると言葉の意味が少しはしっくり来る。なお、ニューラルネットワークの演算の基本は、多入力の積和演算である。各入力にはそれぞれ学習により決定された固有の重み(パラメータ)が掛けられる。その総和を活性化関数に通して次段に出力する。必要に応じて正規化関数の処理を行う。神経細胞モデルと比べると、重み+積がシナプスの機能に相当し、総和+活性化関数+(正規化関数)の演算がニューロンの機能に相当する。神経細胞モデルはもっと複雑であるがニューラルネットではこのように簡素化されている。
なお、画像処理に習い、フィルタと称した、そのフィルタの要素が重みである。
マックスプーリング層
プーリング層の中でよく使われるマックスプーリング層はその入力(前段)の一部である。例えば2x2の矩形領域の4つのユニットの最大値を出力(次段)の1x1の領域に転写する。入力領域全体に同じ操作をスライドしながら繰り返し、出力面が完成する。結果、出力サイズが1/4になる。以降、計算量も1/4になる。
画像認識の効果としては2つあり、共にCNNの大きな特長を成している。1つは視点がミクロからマクロに拡大する点である。図6ではサイズが小さくなる。しかしその要素である上述の1x1領域はマックスプーリング処理前のよりマクロな2x2を代表している。すなわちより大きな領域で特徴を捉えることが可能となる。もう1つは入力画像内の対象物(ひまわり)の幾何(大小、回転、シフト)変化に対する不変性をもたらす。すなわち対象物(ひまわり)の入力画面内での位置、大きさによらず、また回転しても“ひまわり”と認識できる。マックスプーリングを後述するCNNの代表的なモデルのAlexNetは3回、VGGNetは5回、そしてGoogLeNetは4回(ただし、Version1ではInception Layer内にSlideが1のプーリング層を多用している)使用する。ResNetでは1回使用する。ちなみに畳込み層のフィルタ操作も似通っているので上記の2つの効果を畳込み層に織り込む事が可能と考えられる。とするならば、マックスプーリング層はなくてもよい可能性もある。ただし内部はよりブラックボックス化する。
活性化関数
活性化関数は、神経細胞のように演算(積和)の結果を非線形に変換する関数である。種々の非線形関数が提案されてきた歴史があるが、その意味合いは一言では捉えにくい。実は学習時の誤差逆伝播法適用の際の微分処理がスマートに行えることが関数に求められるようだ。WikiPedia(参考資料15)では、「人工神経の活性化関数は、ネットワークを強化または単純化するような特性を持つものが選ばれる」と書かれている。2015年5月雑誌Natureにランプ関数のReLU(Rectified Linear Unit:正の値はそのままスルーし、負の値は0と見なす:参考資料6、8)が最も使われてかつより高速に学習すると書かれている(Y. LeCun, Y. Bengio, G. Hinton共著:参考資料16)。現在ほとんどのモデルがReLUを使用している。
正規化関数
正規化関数に関しては余り使われていなかったようだが、2015年3月に提案されたBatch Normalization(2.3節で簡単に説明)はよく使われている(GoogLeNet、ResNet)。また、2.8節で説明するBinarized Netでは重要な意味を持っているらしい。
特徴マップ数(Nif、Nof)
図6の特徴抽出部を通過することにより「ひまわり」の画像から複数の特徴マップを抽出する。なお、Nof(Number of output feature maps)は層の出力側の特徴マップの数で、Nif(Number of input feature maps)は入力側の特徴マップ数である。活性化関数、正規化関数、さらにプーリング層を経てもマップ数Nofは変わらない。
(2) 分類器
全結合層
後段の分類器に引き渡す際に「ひまわり」の特徴マップを1次元のベクトルに並べ替える。後段の分類器では3個(1個もあり)程度の全結合層(対向する2個のベクトルの全ユニットが全て結合)が次々と仕分けを行い分類(多クラス化)して最初の画像入力が何であるかを判断する。
活性化関数Softmax
その判断は最終段のNo個の出力値で判定する(No個:Number of output クラス数の個数:ILSVRC/Imagenetのベンチマークの一般物体認識のクラス数は1000個)。実は、最終段にはSoftmax(参考資料6)という活性化関数が使用され、値は比率に変換されて出力される仕掛けになっている。Softmaxにはコントラストを強くする働きもある。
クラスと判定
その中の“ひまわり”のクラスの確率が一番高いはずである。例えば、80%。その際他のクラスは“チューリップ”は19%とか、“猫”1%とかになる。入力画像はひまわりに一番似ていたが、実は入力画像のひまわりの一部、例えば葉っぱの形状がチューリップ葉っぱに少し似ていたと判定され、チューリップの確率が19%の結果になったという感じである。ちなみにここで説明した前段の特徴抽出部は通常複数回繰り返され、特徴マップをミクロな視点からマクロな視点へと変えて行く。例としてはひまわりから離れるが、人間なら視点がミクロな耳という小さなものから、大きくなり頭で、さらにはマクロな体でという流れである。より大局的に特徴を捉えて分類している。
(3) クラスとは、そして学習とは
最初は画像を入れると大きな誤差が出る
ここでクラスとは何かということを簡単に説明する。事前に学習のフェーズで、例えば人間がどう見ても“ひまわり”と思える画像を1000枚揃えて、上記の図6のネットワークの左側から入力する。出力は、ひまわりのクラス、チューリップのクラス、猫のクラスの3つがあるとする。これらのクラス名は前もって人間が決める。学習の最初の1枚目では、ひまわりクラスの確率は仮に33%とする(3クラスだったら平均は33%)。理想的な出力は、ひまわりのクラスは100%で他のクラスは0%のはずである。その誤差分(100-33) %を相殺するために、よりひまわりのクラスの比率が上がるように中間のネットワークの重みを調整する。通常一度にドンとはやらず石橋を叩くようにじわじわやる。
パチンコの釘師と誤差逆伝播法
学習の方法はパチンコの釘師の仕事に似ている。通常、閉店後に行う。盤面の無数の釘をハンマーで叩いて角度を微調し、パチンコ玉の流れを変え、ホール穴に入る確率を調整する仕事である。パチンコ店のもうけに直結する。ひと釘直したら、またパチンコ玉を飛ばして様子を見る。ひと釘毎、盤面全面丁寧に調整して行く。パチンコのホール穴に近い釘ほど入る確率に大きく影響するのが通常である。故に、ホール穴に近い図6でいうと出力側から逆方向に、釘を微調(微分)してちょっとした入り具合の違い(出力の誤差分)を盤面(ネットワーク全体)に分散させる。これが誤差逆伝播法のイメージである(もちろん、計算はニューラルネットワークの関数/導関数を用いて行う)。
(4) 教師有り学習
学習時は、事前に人間が選りすぐった“ひまわり”、“チューリップ”、“猫”を各々例えば1000枚ごと、合計3000枚を流すことによってネットワークが確定(重み決め:重みに関しては次節で説明する)する。と同時に出力側が学習前は名ばかりであったが名に恥じぬ真の3つのクラスに成長する。これがいわゆる教師有り学習である。教師有り学習は、作業的には教師画像(クラスが事前に決められた画像)の実行と誤差逆伝播法による重みの微調の2つの作業の気が遠くなるほどの繰り返しである。これが自動でかつタスク目的によらず汎用的にできるのが誤差逆伝播法の優れた点である。以上がニューラルネットワークの学習のイメージである。そこに種々の技法(2.3節で一部紹介)が編み出され多層(3層以上への展開が困難な冬の時代があったが)への展開が可能になった。これが深層学習(ディープラーニング)ある。その技法の内容は2.3節で紹介するが、多くが対処療法的に見える。遠からず人間の脳の機能を模倣しているとは言え、数式処理の無機質な技法の集団に見える。しかし、それ故に汎用的で広範なタスクに展開できると理解している。
(5) 学習した知識は重み(パラメータ)に蓄えられる
畳込み層とクラス化層(全結合層)だけが重み(パラメータ)を持つことから重要である。その重みの数はLSIのチップサイズ、スピード、そしてパワーに直結する。
なお、層のカウントは、多くの場合は重み(以降重みを実装する説明の際にはパラメータと称す)を有する層で数える。図6は畳込み層とクラス化層(全結合層)の2層とカウントされる。プーリング層はカウントしないのが通例のようである。
2.2 CNN基本構成(2)〜ネットワークとパラメータ〜
第1章でも紹介したとおり、ディープラーニングにとって記念碑的と言われているCNNのモデルであるAlexNetを用いて、データのフローとパラメータの働きを説明する。
(1) データの変換フロー
図7にAlexNet(参考資料23)のネットワーク(上段)、パラメータ・重み(中段)、そして単純処理(下段)を示す。左側から画像(犬、Walker Hound)が入力され、右に向かい処理される。右側の結果は、クラスごとに比率(図7右側の挿入図の棒グラフ、1000クラスの中で5クラスの結果を表示)で示される。畳込み層が5回繰り返される。プーリング層は3回である。後段部には、クラス化を担う全結合層(FC1は9216と4096の全結合)が3回ある。活性化関数としてはReLUが、また最終端にSoftmaxが使わる。前節でも述べたように、重要なのは畳込み層(以降Conv層と表示)とクラス化を行う全結合層(Fully Connected層)の積和演算回数とその際に使用されるパラメータの数である。パラメータ数は総数62M個、積和演算回数は11億4000万回(1枚の画像処理)である。なお、ネットワークは前段部の特徴抽出部では3次元での演算を行い、後段部では1次元となる。パラメータは、特徴抽出部では3次元のパラメータを特徴マップ数分持つと表現される。実質は4次元である。
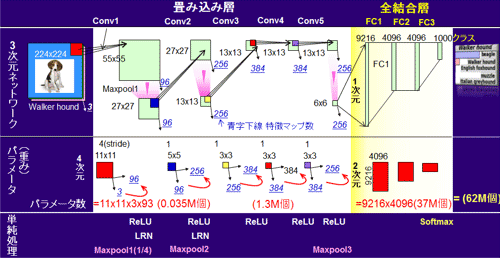
図7 CNNネットワークとフィルタの詳細
(2) 積和演算回数とパラメータ数を見積もる
積和演算の回数とパラメータ数に着目し説明する。最初のConv1層の積和演算の回数は入力3x(224x224)から出力96x(55x55)への接続数の総和となる。接続数の総和は3x(11x11)x(55x55)x96となる。接続の計算は入力224x224を使わず、フィルタサイズ11x11を基に計算する。フィルタがStride 4(ステップが4ユニット分で、左右、上下に移動)で移動し、55x55回繰り返し使用(接続)される。後は、入力側、出力側のマップ数3と96を掛ける。
パラメータ数の算出方法に関して説明する。入力に対して11x11のフィルタ演算(Matrix Multiplications)を55x55回行い、かつRGB 3回分繰り返す。さらに同じことを出力側のマップ数96回繰り返す。パラメータ数は、3x(11x11)x96となる。
積和演算の回数と、パラメータ数の差は55x55の有無になる。CNNの場合にはフィルタをスライドしても同じもの(重み共有:Weight sharing、参考資料6の89頁)を使い回すのがその有無の理由である。その使い回しの回数は出力のサイズ55x55に等しい。結果、演算数に対して2〜3桁少ないパラメータ(メモリ量:詳細は2.6節)数でよいことになりハードウェアへの負担も少なくなる。昨今CNNが急激に発展した理由の一つである。逆にCNNを使用せず別のアルゴリズムの使用を考えると、場合によっては2〜3桁上の性能を持つハードウェアが必要となることを意味する(2.8節参照)。
逆に、後段部の全結合部分では単なる掛け算(例えば 9216x4096)になる。パラメータ数は多く、ネット全体の90%前後(AlexNetでは94%:2.5節を参照)を後段部が占める。
(3) 計算量を減らすちょっと強引な方法、マックスプーリング層
実装の観点から見ると、マックスプーリング層の処理は全体の演算量からみるとほとんど無視できる。Conv1層の後にあり、55x55→27x27とサイズを1/4にしている。すなわちそれ以降の演算量を1/4にする非常においしい機能である。同様の演算量削減の手法としてBottleneck Module(次回2.4節/図10).なるものがある。AlexNetでは使用していないが、1x1のフィルタを使用して特徴マップ数を自由に増減する。昨今多用されている。
2.3 ディープ・ニューラルネットワーク全景〜アルゴリズム・モデル〜
CNNのアルゴリズム・モデル全体は、図8のように展開されてきた。この図は、CNNの動向(参考資料14)をベースに、他のアルゴリズム・モデルと連携した複合機能の動向(参考資料17〜20等)を加え構成した。2016年の動向も加味した。
(1) 全体の展開
展開の方向性は、ディープラーニングもしくはCNNの理論的な「理解」をより深めようとする動き、次に認識率アップをとことん追求する「高性能化」の動き、さらには、他のアルゴリズムとの組み合わせによる「複合機能化(マルチ)」の3つに大別される。その他に、アルゴリズム(特にCNN)の潜在能力発掘による「高機能化」の動きがある。これはネットワークの内部の状態・動きを深く探ることにより顕在化・発展した「理解」追求の中で生まれた成果と見ることもできる。

図8 ディープ・ニューラルネットワークの全景(アルゴリズム・モデル) 2012年以降に着目.
(2) 高性能化
「高性能化」の動きは<技法>、<構成>、そして<高速化・コンパクト化>の3つに分解される。
<技法> 1つ目はディープラーニングのコア技術である多層(ディープ)での学習(ラーニング)を容易にした各種の<技法>である(詳しくは、参考資料8、6を参照)。数多くあるが、図8に記されているいくつかの技法を簡単に説明する。
Dropoutは過学習を制御すべく、学習時に中間層のユニットの値を一定の割合で0にし、結合を欠落させる手法である。AlexNetで使用されており現在も主流である。それに対してDrop Connectは結合の重み自体を0にする手法である。この2つにより、学習時に例えば、本来はぎちぎちに接続している全結合層の結合を少し疎らにしてネット自体に柔軟性を持たせることができる。人間で例えるならば、「頭が固いと応用が利かない」という性格を直すようなモノである。
転移学習は学習の方法を関連する異種のタスクに転用する一般的な技法のことを指し、その中でFine Tuningは別のタスクで学習済みのネットワークを目的のタスクの学習のために再学習することを指す。例えば、「猫の種別の画像認識」の学習済みのネットを「家の種類の識別」に転用する。このことにより家の教師サンプルは少なくて済む。人間で例えるならば、基礎がしっかりできていれば応用は簡単といったイメージである(ポルトガル語が話せる人は、スペイン語も簡単に習得できることに近い)。
2015年に発表(参考資料31)された正規化手法のひとつであるBatch Normalizationを使用することにより、大きな学習係数(誤差を比較的大胆に逆伝播させる)が、使用可能となり学習の収束を早くすることが可能になった。そのために入力サンプルの集合(Batch)に対する中間層の出力の共変量シフトを小さくする正規化の一手法を取り入れる(参考資料14)。ネットワークの一つの構成要素である。最後のKnowledge Distillation(知識抽出)は大規模モデルを小規模モデルに置換する手法である。
<構成>と<高速化・コンパクト化>
次に<構成>要素である畳込み層、重み/カーネル、そしてプーリング層等の工夫によるネットワークモデルの進化がある(次節以降詳細に説明する)。さらに歴史は長いが昨年末より、表舞台に出てきている<高速化・コンパクト化>の動きがある(2.8節参照方)。その内容はデータとパラメータの低ビット化、圧縮、さらに量子化技術である(通常は32ビット浮動小数点を使用)。スピードとパワー共に改善され、効率は2乗程度に比例しインパクトは絶大である。本来半導体の回路構成と強い接点をもつところである。すなわち多くの場合、効果を正しく引き出すためにはハードウェアでの工夫が必要となる。
(3) 複合機能化(システム化)
「複合機能化」はまさしくアプリケーションを成すための「システム化」の動きである。CNNを中心に、前後に複数のディープ・ニューラルネット(例えばRegion Proposal Network参考資料21、Recurrent Neural Network、Reinforcement Learning・・・:図8の脚注参照方)が直列(並列)接続、もしくは取り込まれる形で複数の機能からなるシステムが構成される。直近のディープラーニングで最もホットな領域のひとつである。例としては、車の安心安全の自動予測がある。カメラで、(1)車前方、歩道周辺の物体を捉え(Region Proposal Network:物体形状およびその数フレーム分の位置・速度)、(2)その物体を例えば人と識別(CNN)、(3)その人の動きから現時点より数フレーム先の動きを、事前に学習した人の動作の記憶を基に計算(RNN:参考資料22)して、人が歩道に出てくると先読みしドライバーに警告を発する。(1)〜(3)の3つのディープ・ニューラルネットワークでシステムが構成される。なお、(1)、(2)、(3)のニューラルネットワークにおいて、3連結で実装された報告は現時点では出ていないと思われる。昨年(1)+(2)が合体され、一つのネットワークになり精度が良くかつ処理時間が圧倒的に速く(Faster)なっているFaster R-CNN (Faster Region-based CNN 参考資料21)が発表されている。図8の下側に、代表的ニューラルネットワーク・アルゴリズムとの関連(いくつかの横棒)を示した。細かい説明は割愛する。
(4) 将来に向けて(Missing Parts)
今後必要とされる(現在は実現していない、もしくはまだ先と考えられているもの:図中の赤い矢印に方向性)のは、自ら環境をルール化して自律的に予測するための技術、そのための教師無し学習の充実、さらには概念を形成できる自然言語処理の進歩と言われている。これらの少しでも加わるとかなり知的レベルが上がってくると理解している。現在は、上述の「(2)で人として認識(CNN)」と書いているが実は、事前に学習した中という狭い範囲で物体AもしくはクラスAと識別しているだけである。
本章で取り扱うのは、図8の「高性能化」の中の<構成>と<高速化・コンパクト化>の2つである。次回はCNNの代表的ネットワークモデルであるAlexNetからGoogLeNet、ResNetの説明を通して、LSI実装の勘所を探る。
なお、次章(第3章)以降では公知の情報を基に認識及び時系列処理用ニューロチップ/LSIの回路アーキテクチャを説明する。またそれらの説明を通して可能な範囲で各アルゴリズム・モデルのアプリケーションへの実装アーキテクチャも概説する。
参考資料
1〜9までは、「ニューロチップ概説 〜いよいよ半導体の出番(1-1)」を参照
10〜13までは、「ニューロチップ概説 〜いよいよ半導体の出番(1-2)」を参照
- 岡谷 貴之, 「画像認識のための深層学習の研究動向 −畳み込みニューラルネットワークとその利用法の発展−」, 人工知能学会誌 31巻2号(2016年3月), 169-179頁.
- WikiPedia, “活性化関数”
- Y. LeCun, Y. Bengio, G. Hinton “Review: Deep Learning”, Nature 521, 436-444 (28 May 2015), 深層学習の3教祖によるReviewである。
- 尾形 哲也, 「ロボティクスと深層学習」, 人工知能学会誌 31巻2号(2016年3月), 210-215頁.
- 岡谷 貴之, 「深層学習」, 111-130頁, 第7章「再帰型ニューラルネット」 (機械学習プロフェッショナルシリーズ)、講談社、2015年4月8日 (再掲).
- 松元 叡一, 「分散深層強化学習でロボット制御」, Preferred Research (Preferred Infrastructure Inc,), 2015年6月10日
- 「ゼロからDeepまで学ぶ強化学習」, Qiita, 2016年6月7日
- Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”, 2016年1月6日(ver.3).
- Kyuho J. Lee+, “A 502GOPS and 0.984mW Dual-Mode ADAS SoC with RNN-FIS Engine for Intention Prediction in Automotive Black-Box System”, 2016 IEEE International Solid-State Circuits Conference, Session 14.2, p256-259, 2016年2月.
- Alex Krizhevsky, Geoffrey E. Hinton, University of Toronto, “ImageNet Classification with Deep Convolutional Neural Networks”, (Advances in Neural Information Processing Systems 25 (NIPS 2012)), 20121210.

