ニューロチップ概説 〜いよいよ半導体の出番(1-1)
クラウド利用のIoTシステムの進展と、ビッグデータ解析、Google検索などから人工知能(Artificial Intelligence)やコグニティブコンピューティングが注目されるようになってきた。学習機能を持つ人工知能ではニューラルネットワークのモデルで学習機能(ディープラーニング)を実現している。AIのカギとなるニューラルネットワークのアーキテクチャはもちろん、シリコン半導体上に実現する。この寄稿では、元半導体理工学研究センター(STARC)/東芝の半導体エンジニアであった百瀬啓氏がニューロチップについて解説する。(セミコンポータル編集室)
著者: 元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
はじめに
ここ1〜2年のディープラーニングの進展はすばらしく、押し寄せる波はまさに「ディープインパクト」である。認識(映像、音声、データ)でも運動でもエンドツーエンドで処理を行うようになる。入力(エンド)と出力(エンド)の間には「匠」のアルゴリズムも、数百年来物体世界を支配した運動方程式も見えなくなり、蜂や鳥の様にドローン(進化型)が花畑や林の中を飛び回るようになる。あっという間の進化のスピードによって「びっくりポン」状態になる。さらにこれからは自慢の匠の技も不要となり、このままでは産業・技術・個人レベルでのイノベーションジレンマが発生、大きなディープインパクトに飲まれてしまいそうだ。
より素速く(2桁以上の改善)、より詳細で(コンテンツ認識)、魅力的な(合成、色彩付け等)、懐の深さがある(多入力)、しかも動きを捉え自律化可能とする(マルチモーダル)極めて豊かな認識技術が確立されている。さらにこの成功が引き金となり、より自律性を強化する学習方法(強化学習)が加わり、新しい運動法則(エンドツーエンド・ラーニング)がデビュー(完成)する。人間の知識・知恵を習得するまでに至っておらず人工知能の頂きから見ると2〜3合目でしかないが、大きなビジネスチャンスを持つベースキャンプの入口に立っている状態だといえる。
さらに既存の半導体関連技術に対する部分的かつ包括的な見直しも魅力的である。例えば映像でのエンコード、デコード、トランスコード、合成、トランスフォーム(Morphing)、検索、ノイズ除去等々を、ディープラーニングで再構築することも楽しいかもしれない(既にやられている?)。音声、データでも同様で、また長年の課題も解決できるかもしれない。センシングから認識の部分を包括的に見直すことも興味ある課題である。ニューロモルフィック/ニューロインフォマティクスや、生物昆虫まで視野に入れたバイオミメティクスへの注視がキーとなる。
本報告の主張はサブタイトルにあるように「いよいよ満を持しての半導体の出番」である。サーバー系はもとより、エッジ系への展開が始まる。自律運動系やモバイルユビキタス系、さらには環境系(IoT・・・)と多くの分野に波及しよう。また今後の半導体の戦術・戦略策定の作業の序論となれば幸いだと考えている(注釈1)。その策定スコープは各々の市場領域における製品群「メモリ、メモリ混載、論理LSI(CPU・GPU・FPGA・カスタム)、IP、センサとの融合等」、および技術(材料、デバイス、回路、パッケージ/組み立て等)、さらには市場・動向に及ぶ。
この記事は、多くの関係者に直接的、間接的にご教授いただいた内容をベースとしている。特に2つの流派「脳型機械学習ハードウェア(すなわちディープラーニング)とニューロモルフィック工学」の存在の認識は、半導体技術者として全体把握のための基礎知識として重要である(参考資料1)。以下のように分けて報告を予定している。
第1章・・・ニューロチップを取り巻く概況〜いよいよ半導体の出番(1-1)
ニューロチップを取り巻く概況〜いよいよ半導体の出番(1-2)
第2章・・・ディープ・ニューラルネットワークのニューロチップへの実装〜その勘所は!!〜
第3章・・・回路アーキテクチャ、デバイス、そして将来動向(仮題)
第1章では、ディープラーイング、ニューロチップの昨今の状況に関して概説する。第2章は、今回簡単に紹介するニューロチップからみたアプリケーションの具体的な機能、及び実装されているアルゴリズムに関して可能な範囲でまとめて報告予定である。第3章では、より半導体に近いスタンスで報告する。なお、重要な用語に関して、(用語解説)をつけたので予めご一読いただきたい。
用語解説
ニューラルネットワーク、ディープラーニング: ニューラルネットワークに関しては、ニューロモルフィック(主にスパイキングニューラルネットワーク)も含めて広い範囲に適用可能な用語だが、昨今はディープラーニングと結びつけて語られる関係からかなり狭義な意味として使われているようだ。断りのない限りディープラーニングとニューラルネットワークは同じ仲間の言葉として使用する。
学習(learning)と実行(inference):英語に関して学習はtraining/learningである。実行は主にinference(他にExecution/running)が使われる。この関係から、実行の代わりにまれに推論(inference)が日本語で使われることもある。実行は瞬間的に終わるが、学習は106〜1010倍ほど時間が掛かる。パラメータ数×学習回数(収束まで)×(学習用のサンプル)×α(種々の短縮テクニック)。
教師有り学習(supervised)と教師無し学習(unsupervised):今回の解説記事では、断りのない限り「教師有り学習」を扱う。国が教師を育成し、学校でその教師が学生に勉強をさせて覚え込ませるが、その学生が実社会にでて働く(実行)わけである(実際は教師の代わりに教師パターンを使用して学習する)。脱線するが、2012年(今振り返ると天下分け目の年)以降下火になっている「教師無し学習」を見直そうという機運が起こっている様である。
サーバーとエッジ:サーバーでは、学習(実行も)を如何に高速に行えるか! が唯一最大の関心事である。エッジ側では、実行が主体で、高速性よりも低消費なり、必要な回路規模が関心事となる。(注:エッジリッチ/分散学習の考え方もある:参考資料2)
第1章:ニューロチップを取り巻く概況 〜いよいよ半導体の出番
1.1 アルゴリズム進化/システム応用の広がりは指数関数的
1.2 満を持して半導体登場
1.3 エッジ系でのビジネス展開が加速 〜車、ドローン、ロボット 自律系の取り込みも〜
1.4 低消費電力化
1.5 2つの流派があることを常に認識しておく必要がある
1.6 まだ2合目、3合目に到達した段階
1.1 アルゴリズム進化/システム応用の広がりは指数関数的
繰り返しになるが、アルゴリズムの進歩とその応用実証展開の速さは、ディープラーニングの最前線の技術者の方さえ驚くほど、加速度的に進歩しているのではないかと思う。課題解決までの速さ、学会(含むariXiv)論文の件数や進化の度合い、世界・日本各地でぽんぽんと発信されるAI関連の研究所の活動、そういった情報も含んだウェブ上での関連記事の遭遇の頻度の増加等、まさしく肌(頭で)で進化の度合い(イメージとしては全世界で何万、何十万のディープラーニング技術者が寝食を忘れてうごめいている状況)を感じる。その勢いは2016年に入りますます激しくなっている。うごめきは百万人規模のような、いわゆる指数関数的である。
その感覚を定量的に示しているものが、Googleが2015年末頃より紹介している「Growing use of deep learning at Google」なる図である。オリジナルはGoogleの講演資料(参考資料3)、NIPS2015のキーノートスピーチ(参考資料4)を参照していただきたい。ディープラーニングのモデルを含むディレクトリー数の2012年からの増加をグラフにしたものだ。その値を転載したグラフが図1(a)の上図の上昇線(白線)となる。2015年末から2016年に掛けて指数関数的に増加、見ようによっては今が特異点にも見える(ただし、白文字の機能応用は必ずしもGoogleとは関係していない事柄も含んでいる)。
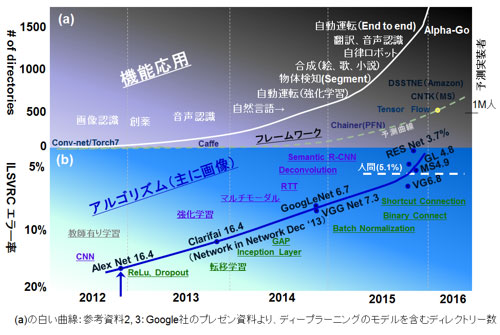
図1: (a) 2012年以降のディープラーニングの展開のトレンドおよびフレームワークの普及
(b) 2012年以降のILSVRCでのエラー率 改善の推移
この特異点を考えるときに、要因はよく言われているように(参考資料7)以下になる。
1.Imagenetの貢献・・・卓越した組織力(ラベル付きイメージ約1400万枚を擁する競技会)
2.CNNアルゴリズム等・・・良きアルゴリズム
3.GPGPUの貢献・・・良きハード
4.フレームワークの貢献・・・良きソフト
-CNN:主に画像認識用に使われる畳込みニューラルネットワーク(Convolutional Neural Network)
-Imagenet:ImageNet Large Scale Visual Recognition Competition ILSVRC 画像認識のオリンピック。
いくつもの競技があり、今回データとして使っているのは100m競技にも匹敵する一般物体認識。
図1(b)に、ImagenetでのCNNをベースとしたネットワークでの一般物体認識のエラー率(1000クラスの仕分け、Top-5 Error)の2012年のAlex Net以降の推移を示す。Alex NetのNIPS2012での会場の雰囲気に関しては(参考資料5)が詳しい。また多くの技術著書/技術情報等がある(参考資料6、7)。この記念碑的ネットワークを原点として、エラー率は改善、2015年には人間のエラー率5.1%を越えた。ディープラーニングの基本的な技術革新(図中の緑字:ReLu、Dropout・・・)に各機関の改善努力(VGG Net/GoogLeNet等々)がもたらしたためである。今後は難易度が高くなるのでないかという気がする(注釈2)。
この画像認識のCNNが磨かれて来ると同時に、もう一つのアルゴリズムの進化の軸として機能性の向上がある。その機能性の向上を、図1(b)の曲線の上側に記している。特にCNNの脇を固める高機能化を目指したアルゴリズムの進化(多くは1980年代の発明がその元)が、応用の範囲を一層広げている。
この進化の過程で重要な点に、アルゴリズムを実世界上にエミュレートするソフトウェアツールであるフレームワークの存在がある。図1(a)の右側に8つほどのフレームワークを点在、また実際にツールを実装した人の人数の想定トレンドを示した。去年より、日本のPFN 社(株式会社Preferred Network)のChainer、GoogleのTensorFlow、MSのCNTK、さらに5月のAmazonのDSSTNEとこぞってオープン化されている。これらフレームワークには既存のネットワークがライブラリーとして入っているものも多くPythonに関して知識のある技術者なら今日からでも、著名なネットワーク(例えばAlexNet)を自分のパソコン上に実装できる(参考資料8)。この結果、ディープラーニングにタッチした技術者は全世界で百万人(参考資料9)を軽く越えたと予想している。
全体を概観するとディープラーニングの仕様と方向性は以下の様に固まってきている。
- フェーズ1 (2012年)・・・CNN 画像認識においてAlexNetがImagenetで前年を上回る正解率を達成
- フェーズ2 (2014年)・・・CNNの手法改良と、CNNの脇を固めるアルゴリズムの進化と自律系の適用
RNN (Recurrent neural network)・・・再帰型ニューラルネット(時系列データ処理)
RL (Reinforcement learning)・・・強化学習(行動パターンの強化)
- フェーズ3 (2015年〜) フレームワークのオープン化 Chainer、Tesorflow、CNTKなど
これらを各ステップとして、現在の2016年が特異点を迎えていると考えることができる。
さて、この流れでハードウェア、半導体のポジションはどうなのかがポイントとなる。 - フェーズ4 (201x年) ハードウェア(・・・)
この分野は現時点NVIDIAのGPGPU/FPGAが使われている。この点に関しては次節で説明する。
1.2 満を持して半導体登場
図2にニューロチップ関連(含:GPU/FPGA)の最近の動向を示す。目的別に3種類に分けられる。
- 脳神経科学理解のためのニューロモルフィック(生体様)チップ:神経ネットワークモデルを集積回路上に再構築して逆に脳機能を解明しようとすることを目的としたシミュレータ・エミュレータチップ(参考資料1および 次回1.5節)。脳の高性能・高機能性の実装可能性を秘めた分野である。特にIBMのTrueNorthはエッジ応用(とりあえずは)をターゲットとしたフラッグチップとしての性格も持ち合わせている(注釈3)。なお、デバイス開発は活発で昨年12月のIEDMでは2つのセッションがこの分野関連となっていた。
- エッジ用チップ:実行が主体で低消費電力性が必要である。今年に入り発表が急激に増えている。次回少し詳しく述べる。学習用が1チップある(KAIST2015 ISSCC)。
- サーバー用チップ:学習用で高速性が第一。データセンター用で、従来のCPUからGPGPUもしくはFPGAに切り替わりつつある。メモリバンド幅を拡大した方式(HBM2→P100、Xilinx)が技術の目玉である。それ以外は、中国科学院(CAS)のDaDianNaoで、2014年12月(MICRO47)に発表されたDRAM混載の学習用チップ(Machine Learning Super Computer: CADベース、チップ化は計画のみ)である。最新のTeslaベースのGPU(P100)よりも10倍程度の高速性があり、パワーも一桁以上小さい。また5月18日のGoogle I/O 2016にてGoogleのカスタムチップTPU (Tensor Processing Unit:Tesorflowに対応)に関しての発表(チップは1年前)があったが詳細は次回以降に報告する予定。
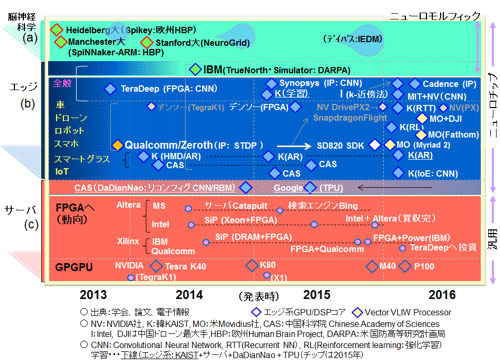
図2: ニューロチップ関連の最近のトレンド
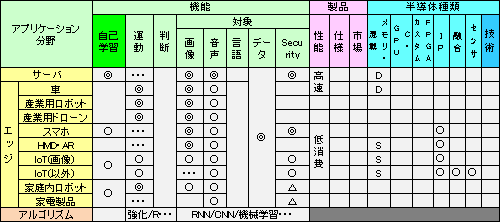
注釈1:想定市場、機能と半導体関連の事項との関連図。 ◎・・・有り、○・・・可能性有り、空白・・・不明
注釈2:人間の画像のクラス分けの認識(例えば、この写真は野良猫ではなくシャム猫だ!と当てる。実際は1000クラスの仕分け、Top-5 Error)能力がエラー率5.1%のようだが(参考資料7)、そもそも正解(Ground Truth)も人間(1名の結果?)が与えているので5.1%以下は正解にも確率(ガウス分布)が掛かっているはず。ということで大雑把に1σ位の3.4%を特異点としてグラフはプロットしている。近づけば難易度がぐっと高くなるはず。今後は他の競技種目が脚光を浴びるのかもしれない。
注釈3:ニューロモルフィックチップの工学的実用化をめざし、別の流派であるディープラーニングの技法の適用を目指す動きがある。その際に2つの課題がある。誤差逆伝播法「BP法:Back Propagation」の適用実証とバイナリー値の定量的解釈である。ここ数ヵ月(2015年11月〜16年4月)、IBM 自らまた、モントリオール大学(Bengio教授のグループ:Binary Connect/Binarized network)等の研究で前進が見られ、二つの流派に架け橋ができそうな雰囲気がある。なお、ディープラーニングとの架け橋が必要かどうかも議論の余地のある点である。
参考資料
- 浅井哲也, 「ニューロモルフィック工学・脳型機械学習ハードウェアの行方」, 日本神経回路学会誌, Vol. 22 (2015) No. 4 p. 162-169. 2015年12月
- 岡野原大輔, 「今後10年の情報処理アーキテクチャーを探る」, 日経エレクトロニクス, 95〜105頁, 2015年5月号。
- 佐藤一憲, “Machine Intelligence at Google Scale: Vision/Speech API, TensorFlow and Cloud Machine Learning”, 2016年4月4日
- Jeff Dean and Oriol Vinyals, “Large Scale Distributed Systems for Training Neural Networks”, NIPS 2015 Tutorial
- 佐藤育郎, 「ディープラーニングの車載応用にむけて」, 2016年1月8日
- 岡谷貴之, 「深層学習」 (機械学習プロフェッショナルシリーズ)、講談社、2015年4月8日。
- 中山英樹, 「深層畳み込みニューラルネットワークによる画像特徴抽出と転移学習」, 電子情報通信学会音声研究会7月研究会, 2015. http://www.nlab.ci.i.u-tokyo.ac.jp/pdf/CNN_survey.pdf 2015年7月。
- 山下隆義, 「イラストで学ぶディープラーニング」, KS情報科学専門書, 講談社, 2016年2月22日。
- ITmediaニュース, 「GoogleとUDACITY、「TensorFlow」で学ぶディープラーニング講座を開設」, UDACITY受講者は100万人を越えた, 2016年1月22日。

