Nvidia、LSI新製品開発短縮に威力を発揮する生成AI「ChipNeMo」を公開
半導体売り上げで急成長しているNvidiaは、生成AIをはじめとするAIコンピューティングのGPUやソフトウエアをさまざまな応用ごとにAIソリューションを提供している。このほどLSI設計期間を短縮するため、チップ設計のための生成AIであるLLM(大規模言語モデル)アシスタントChipNeMo(図1)を開発、IC製品開発に使っていることを「NTTPC GPU Day 生成AI基盤の最前線」の講演で、明らかにした。
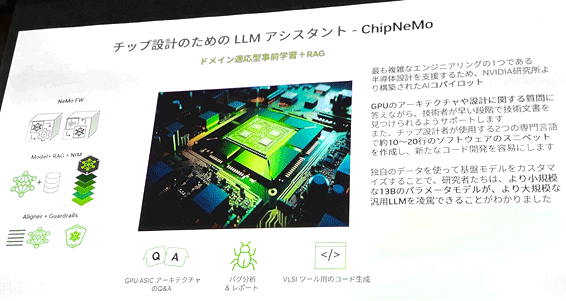
図1 LSI設計のためのLLMアシスタントChipNeMoを開発 出典:Nvidia
Nvidiaは、2022年に生成AIが登場してくるまで、2〜3年に一つの新製品を出していた。しかし生成AIの登場以来、ほぼ毎年一つ新しいGPUやAIチップを出すようになった。その背景の一つは、生成AIを活用していることだった。たた、生成AIと言えども、一からLSI設計の学習を教え込むわけではない。AIで最近よく使われるようになった追加学習を使うのである。
LLMでは、言語をトークンと呼ばれる単位に区切って学習させているが、そのトークンのパラメータ数が大規模になればなるほど学習期間が長くなった。最初のチャットGPTでは1750億パラメータという巨大なデータを学習させるために数千個という大量のGPUを使っても300日程度かかったとされている。そこでできるだけ少ないパラメータで学習させる方が実用的になる。
LSI設計にしてもそのままチャットGPTを使うのではなく、LSI設計に特化したいわばカスタマイズした生成AIを使う方がより正確で短時間で結果が得られる。Nvidiaが開発した生成AI「ChipNeMo」を使えば、GPUのアーキテクチャや設計に関する質問にすぐ答えられ、しかも必要な技術文書を早く見つけてくれる。さらにLSIの設計言語から簡単なスニペット(言語の中から簡単に切り貼りして再利用できる部分)を生成し、コード開発を簡単にしているという。基盤モデルとして700億パラメータのLlama(ラマ)2を使いながら、130億および70億パラメータと少ないChipNeMoチャットモデルが出来たとしている。
一般に、生成AIの学習には、学習させるべきデータの収集から始まり、モデルの事前学習、基盤モデルによる学習、カスタマイズを経て、ファインチューニングで事後学習をさせてから利用(デプロイ)できるようになる(図2)。
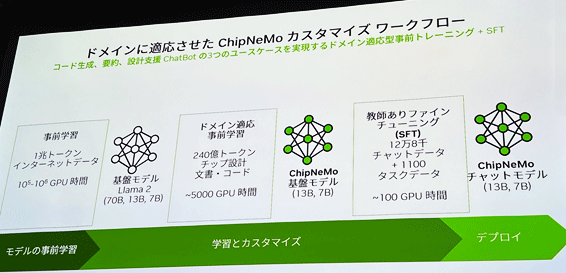
図2 半導体設計用の生成AIプラットフォームChipNeMoの追加学習による手順の例 出典:Nvidia
一般のユースケースではこれだけにとどまらず、NVIDIA NeMo Guardrailsで合法的なことを学習させているかどうかをチェックする。実際に推論して使う場合には NIM(NVIDIA Inference Microservice)を利用すると、すでに構築されたコンテナが附属しており必要なモデルを選択してすぐに使えるようになっている。
Nvidiaの生成AIではコード生成と要約、設計支援のチャットボットという3つの機能を実現している。こういった追加学習でカスタマイズするためのツールもNvidiaは開発しており、RAG(Retrieval-Augmented Generation:検索拡張生成)と呼ぶテクノロジーが威力を発揮する。この技術は外部ソースから取得した情報を用いて、生成 AI モデルの精度と信頼性を向上させるものだという。
NVIDIA NeMo は、カスタマイズされたエンタープライズ グレードの生成 AI モデルの構築に特化した、オープンソースのエンドツーエンド プラットフォームである。LSI設計だけではなく、創薬開発やデータ分析、シミュレーション、ロボティックスやデジタルツインなど様々なAIコンピューティングプラットフォームにさまざまなNeMoプラットフォームがある。

