アーム社が着実に市場を拡大するため三つの新製品をARM Forum 2010で発表
最大手のIPベンダーである英国のアーム社はARM Forum 2010を11月11日に開催、新製品を三つ発表した。このうちハイエンドのグラフィックスIPであるMali-T604グラフィックスプロセッサに関しては記者会見を開いたため、すでに報道したメディアもある。実際に「今回発表した新製品は三つある」(同社COOのGraham Budd氏)。
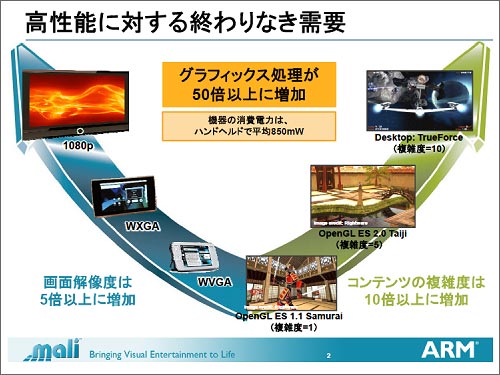
図1 グラフィックス機能への要求は続く
より性能を上げたのがGPU(グラフィックスプロセッサユニット)Mali-T604であるが、残りの二つは、マルチコアによる並列処理をスムーズに行うやすくするためのバスインターコネクトであるCoreLink、そして物理IPとして最適化したCortex-A9を今すぐシリコンにインプリメントするためのパッケージPOP(プロセッサ最適化パック)サービス、である。3〜5年後のスマートフォンやタブレットへの応用を考えた製品としては、Mali-T604とCoreLink、今すぐタブレットを出荷するためのSoCを作りたい、と考えるユーザーにはPOPサービスの利用が可能である。いずれも従来のアーム社の顧客の枠を広げ、数年先の製品から今すぐ使える製品までカバーできるように広げている。
製品発表したMali-T604は果てしないグラフィックス性能への要求に応えるためのIPだ。同社メディアプロセッシング部門製品マネージャーのSteve Steele氏によると、従来の携帯やスマートフォンと比べ解像度はWVGAからHD品質の1080pと比べ5倍以上に増加し、さらにOpenGL ES1.1で設計できる程度のコンテンツから今の要求はその10倍の複雑さに達しているという。しかも携帯機器に使うことを考慮に入れると、パワーバジェットとしては平均850mW以下に抑える必要がある。
消費電力を上げずに性能を上げるため、アームはマルチコアへの拡張性を上げるためのコンピューティング手法の工夫と、グラフィックス画面を表示するためのレンダリングを工夫した。
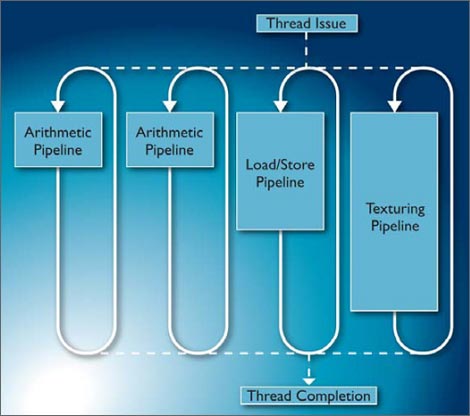
図2 Mali-T604GPUコアの基本アーキテクチャ
コンピューティング能力を上げるため、シングルのGPUコアの中に3種類のパイプライン構造をとり、性能を上げると共にフレキシビリティも上げる設計を採っている。そして最新鋭のプロセッサコアであるCortex-A15とGPU、そしてメモリーを効率よくレイテンシを少なく保つために新製品CoreLinkバスで接続する。グラフィックス機能を上げるため、同時に画面上の「絵」や「影」を塗りつぶすためのシェーダーコアを4個並列に動作させる。それらのコアで実行すべきタスクを割り当て、電力管理も行う役割を持つのがジョブマネージャーである。
こういったマルチコア、マルチスレッド方式のプロセッサアーキテクチャでは共有メモリーであるL2キャッシュのコヒーレンシを高めることが重要なカギを握ることになる。メモリーのコヒーレンシとは、共有メモリーの内容を一致させる技術のこと。マルチコアのような複数のコアで処理する場合、共有メモリーの内容がコアごとにバラバラでは性能に差が大きくなってしまう。このためキャッシュに使うメモリーの内容を同じにしてコアごとのキャッシュミスが起きないようにしておく。このため、共有メモリーを管理するMMU、そしてメモリーのコヒーレンシを管理するSCU(スヌープ制御ユニット)を持つ。これによってシェーダーコア間のコヒーレンシを管理できる。並列処理としては、最大256スレッドまで管理できる。
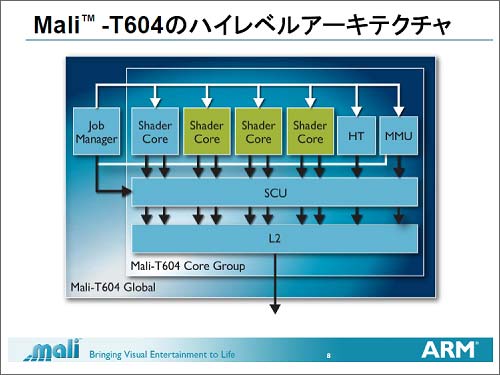
図3 GPUコア1個内も並列処理している
こういった多数のシェーダーコアに適した並列処理をGPUで行うアーキテクチャを構成したことは、実はレンダリング手法とも関連する。消費電力を上げないためにメモリーのバンド幅を減らしているが、そのために1つの画面を例えば4×4分割して、分割した領域をタイルと呼び、その多数のタイルを塗りつぶすために多数のシェーダーコアで並列処理する。このタイルベースアーキテクチャを実行するためにマルチスレッド方式の並列処理を導入した訳だ。
タイルベースアーキテクチャでは、計算順序に優先度を決め、まず表から見えない部分のシェーダーは行わない。次に画面後ろ側にある絵のバックグラウンドを塗りつぶす。そのバックグラウンドに乗っている特徴的な部分のタイルを処理する。この特徴的な部分がタイル間にまたがっていることが多いため、特徴を順位付けしながら特徴のあるタイルだけを処理する。このようにしてレンダリングの必要な部分のタイルから順番に計算していくことで、無駄な計算を行わないように工夫している。
GPUコアはもちろんマルチコアも可能であり、複数のGPUコアをつなぎ、メモリーのコヒーレンシを確保するためにCoreLinkバスを設計した。CoreLinkバスはアーム社が従来から使っているAMBAバスのハイエンド版ともいえるバスで、AMBA4 キャッシュコヒーレントインターコネクト(CCI-400)と呼んでいる。キャッシュの利用効率が高くなりキャッシュミスが減る。ソフトウエアでキャッシュのメンテナンスを行う必要もない。
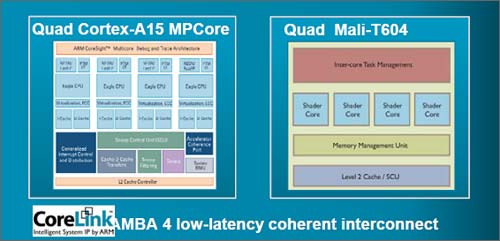
図4 CPUとGPUをつなぎメモリーのコヒーレンシを高めるためのCoreLinkバス
CoreLinkを通じて、GPUからCPUのキャッシュを探しに行くことができ、キャッシュデータの共有化が簡単になる。このため不要なキャッシングをなくすこともでき、計算効率が上がることになる。
現実的なソリューションを欲しい顧客に向けた3番目の新製品であるPOPサービスは、シリコンに回路を焼き付けすぐに動作を実証できるパッケージサービスだが、ファウンドリをパートナーとしてファブレスやIDMの顧客に提供する。例えば、32nmのハイkメタルゲートのサムスンのプロセスを使ってSoCを製造したり、1.7GHzで動作するテキサスインスツルメンツ(TI)のOMAPプロセッサを実現したりしている。SoCをすぐに設計製造したい顧客に適したサービスでCortex-A9の物理IPのほかにARMが認定するベンチマークをテストでき、リファレンス手法も提供する。ファウンドリパートナーとしては、サムスンに加え、TSMC、グローバルファウンドリーズも使える。
参考資料
1) ARM社ニュースリリース
ARM Heralds New Era In Embedded Graphics With Next-Generation Mali GPU

