Nvidiaの最新チップGH200になぜCPUとGPUを集積するのか
NvidiaがComputex Taipeiで生成AI向けの最新チップGH200(図1)を発表し、それを「Grace Hopper」と名付けた。GraceはCPU部分、HopperはGPU部分を指している。実はその前にAMDもMI300Xという生成AI向けのGPUチップを発表しているが、ここでもCPUとGPUを組み合わせて使う。なぜか。

図1 NvidiaのCPUとGPUを集積したGH200 出典:Nvidia
Grace Hopperだけではなく、AMDのMI300シリーズで最初にCES 2023で発表したMI300AもCPU+GPUのAIチップであった。AMDは生成AI向けのAIチップ構成をこの頃からしっかりと考えていた節がある。5月23日には電力効率の良いスパコンTop500に載っている上位10社の内7社がAMDのEPYC CPUとInstinct MI250 AIアクセラレータを使っていると発表した。AMDがスーパーコンピュータやこれからのHPC(High Performance Computing)、AIスーパンコンピュータなどにCPU+GPUのセットを使っていく構えを見せている。
8月にAMDが Instinct MI300Xを発表したときはGPUを大きくしたAIアクセラレータのチップだったが、6月13日には第4世代のEPYCというCPUを発表しており、AIシステムにはCPU+GPUのセットが生きてくると述べている。またMI300は、チップレットを活用してパッケージングした最初のGPU製品であり、AMDは先端パッケージ技術を推し進めていく。
GH200は、図2に示されるように、左側のCPUと右側のGPUをうまく使い分けることによって、効率よく演算できるようにしている。
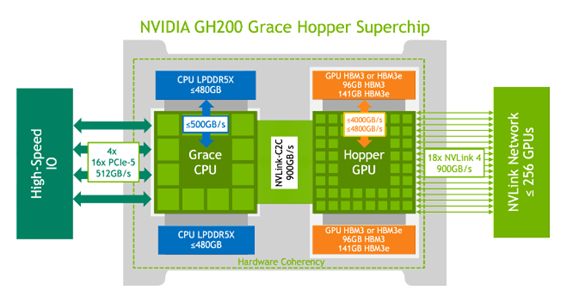
図2 GH200の内部ブロック図 出典:Nvidia Grace Hopper Superchip Architectureホワイトペーパー
上の図では、CPUのメモリとしてLPDDR5Xを、GPUにはHBM3Eを使う。CPUとGPUを900GB/sという超高速のNVLinkでつなぎ、外部のGPUともNVLinkで接続し拡張性を確保する。
NvidiaはCPUとして独自仕様のGraceを使う効果を、x86 CPUとの比較で説明している。CPUメモリのバンド幅は、x86系の150GB/sに対して3倍以上の500GB/sとなり、CPUとGPU間のやり取り用のデータ幅はx86系の128GB/sに対してNVLink-C2Cを使い900GB/s、と独自仕様のCPUでバンド幅を広げることができた。さらに他のGH200とも接続してシステムを拡張する場合もNVLinkを使って接続する。
さらにメモリをCPUとGPUで共有できるように工夫している。そのために物理メモリに直接つなぐのではなく、メモリの変換テーブルを作り、ここを介して記憶させる物理メモリ(HBMやLPDDR5x)ページに飛ぶようにした。CPUとGPUは完全に同じメモリセルにアクセスできる。
AIの演算処理にGPUだけではなくCPUも利用するには訳がある。この場合CPUは制御だけではなく演算機能も欠かせないため、最大128ビットまで拡張できるハイエンドのArm CPUコアであるArm Neoverse V2 CPUコアを72個使っている。
一般には、GPUには大量の積和演算器とメモリが集積されており、演算だけに専念するGPUで行列演算を行うことが多い。特に積和演算器を大量に集積しているGPUは、密な行列演算には適している。
しかし、疎の演算ではレイテンシに時間がかかりすぎGPUは適さない。ニューラルネットワークでは、重みやデータ×0=0の計算が実に多い。これをGPUで行列計算することは結果がゼロという無駄を計算することになる。無駄な計算をしなくて済むように疎の行列演算ではCPUで対応する。これから時間のかかる生成AIの学習には、無駄なく処理時間を短くするために、CPUとGPUをセットで使うことが欠かせなくなるだろう。
参考資料
1. "NVIDIA Grace CPU Superchip Whitepaper", Nvidia Whitepaper

