Intel、第4世代のXeonプロセッサで起死回生なるか、3D-IC/EMIBで超高集積
Intelがようやくコード名「Sapphire Rapids」のCPUを第4世代のXeonスケーラブルプロセッサとして量産にこぎつけた。4個のCPUダイをEMIB(Embedded Multi-die Interconnect Bridge)で接続したXeonスケーラブルCPUに加え、ICパッケージ内にHBMメモリを集積したXeon CPU MAXシリーズとGPU MAXシリーズ(コード名Ponte Vecchio)も同時に発表した。

図1 第4世代のIntel Xeonスケーラブルプロセッサ 出典:Intel
この第4世代のプロセッサをIntelは、実際の現場で使うワークロードを最優先したと語り、ワークロードの性能がSPECintなどのベンチマークテストでの性能とは異なることを示した(図2)。つまりこれまでとは違い、「汎用」のCPUではなく、実際のワークロード性能を優先した「準専用的」なプロセッサに仕上げた。
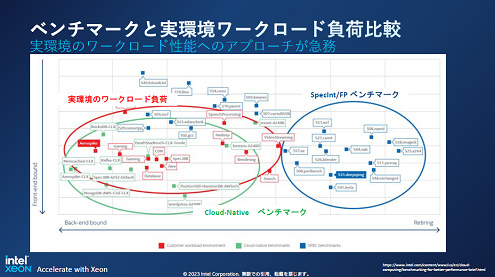
図2 ベンチマークでの性能と実使用での性能は大きく違ってきた 出典:Intel
そのために、CPUコアに加えて、各分野のアクセラレータも集積した(図3)。つまり、汎用のCPUに、AI、通信ネットワーク、ストレージ、データセンター、HPC(High Performance Computing)に特化したアクセラレータを加えた。各分野に適した製品シリーズを提供する。例えば、AI(機械学習)ではAMX(Advanced Matrix Extensions)と呼ぶアクセラレータを搭載しており、CPUの演算負荷を軽くする。このアクセラレータはTensorFlowやPyTorchなどの言語をサポートする。5G基地局などの通信ネットワークでは、Virtual RAN向けのAVX(Advanced Vector Extensions)アクセラレータを使う。ソフトウエア定義のネットワークで使われるデータプレーン向けのソフトウエア開発用の開発キット(DPDK)を用意する。ストレージシステムからのアクセスにはDSA(Data Storage Accelerator)アクセラレータなどを利用できる。
中でもAI機能はデータセンターでもHPCでもエッジでさえも使われるため、実環境でのプロセッサではAIモデルの大小はあるものの、様々な用途で使われるようになってきた。このため、最近のCPUやSoCには多かれ少なかれ、AI(機械学習)機能が搭載されるようになりつつあり、今回のXeonプロセッサでもAI専用アクセラレータが集積された。

図3 AIや5G通信ネットワーク、ストリーミングなど用途ごとのアクセラレータを集積した 出典:Intel
そして周辺回路には最高速のDDR5メモリ対応や、PCIe5.0の高速シリアルインターフェイス、高速メモリ向けのCXL 1.1次世代I/Oなどのインターフェイスや最大64GBのHBM2eメモリを搭載している。
今回、Xeon スケーラブルプロセッサに加えて出荷し始めたXeon MAXシリーズには、HBM2eメモリをICパッケージ内に内蔵している。この製品はスーパーコンピュータやデータセンターなどのHPC(High Performance Computing)向けの製品シリーズである。
それぞれのチップのアーキテクチャは図4のように構成されている。第4世代のXeonスケーラブルプロセッサには3種類あり、モノリシックなCPUのMCCシリーズと、4タイルのCPUをEMIBで接続したXCC、さらにこのXCCにHBMを4個搭載した製品がMAXシリーズである。XCCは最大60個のCPUコアからなる。
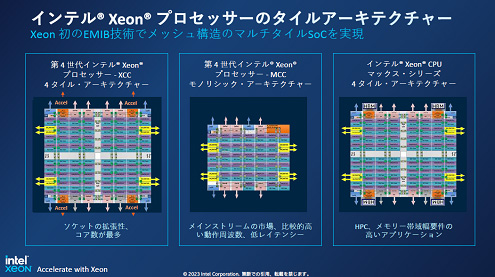
図4 第4世代Intel Xeonスケーラブルプロセッサには3種類 左と右のXCC製品とMAXシリーズは4チップレットをEMIB(白い配線部分)で接続している 出典:Intel
これらのCPUに加えて発表した、データセンター向けのGPUのMAXシリーズはコード名Ponte Vecchioと名付けられ、先端パッケージ技術で作られている。このGPUは、Intelの3D-IC技術であるFoveros技術と、2.5Dで平面上にあるチップ(ダイ)同氏を接続するためのEMIBを使ってチップレット(Intelはタイルと呼んでいる)を接続している。合計1000億トランジスタからなり、アクティブなチップレットが47個、Foveros利用のスタックしたダイが16個、EMIBが11個搭載されている。EMIBは、シリコンインターポーザと違い、シリコン全面を使わず、再配線層と電極パッドを備えたチップ同士の接続だけを目的とする小さな再配線層のシリコンダイである。
日本市場では、京都大学がスーパーコンピュータにXeon MAXシリーズ、筑波大学がXeonスケーラブルプロセッサとOptaneメモリを導入することを決めた。また、Nvidiaからも、従来のデータセンターのサーバよりも25倍も高性能なNvidia DGX H100にはNvidiaのTensor Core GPUを制御する第4世代のXeon スケーラブルプロセッサが搭載されるようになる、という発表があった(参考資料1)。NvidiaのH100サーバ60台以上にXeonスケーラブルプロセッサが使われる。IntelのプロセッサとNvidiaのGPUの組み合わせでH100サーバは従来のCPUだけのデータセンターサーバと比べ、エネルギー効率は3.5倍、TCO(全運用コスト)1/3以下になると見積もられている。
参考資料
1. "The Greenest Generation: NVIDIA, Intel and Partners Supercharge AI Computing Efficiency", Nvidia (2023/01/10)

