性能と拡張性の高いMIMDアーキテクチャのAIチップで勝負するGraphcore
AIプロセッサチップからAIコンピュータシステム(図1)まで手掛けるGraphcoreが2021年に入り日本でも活動に力を入れている。機械学習に適した超並列処理のMIMDアーキテクチャを使い、AI性能が極めて高いのが特長だ。すでに韓国通信オペレータのKTでネットワーク効率を上げ、Microsoft Azureクラウド上での医療画像分類認識で最新GPUよりも12倍も高速という実績を見せている。

図1 IPUを4個搭載したAIボード「IPU-GC200、M2000」 この1枚のボードの性能は1P(ペタ)FLOPS 出典:Graphcore Corp.
英国のハイテク街の一つ、ブリストルに本社を持つGraphcoreは、世界各地にセールスオフィスを置き、開発したAIマシンの普及に努めている。2016年に設立されたばかりのこのスタートアップは7.1億ドルの資金調達に成功しているが、企業価値は27.7億ドルに及ぶと見積もられている。
多くのVC(Venture Capital)やGoogle、OpenAI、DeepMindなど企業投資会社がここまで熱心に投資するのは、Graphcoreのテクノロジーに惚れ込んだからであろう。通信分野では、ネットワーク性能の最適化にAIを使うことがよく行われているが、ネットワークの状態変化から性能パターンを分析してこれから先の性能を予測する。通信トラフィックが集中しそうになれば事前に察知して障害を修正しておくことができる。現在、最先端でかつ普及しているNvidiaのGPU(V100)と常に比較しているが、ネットワークの分析では短いレイテンシで約260倍速い。また、MicrosoftのAI技術を使っての医療画像の解析でGPUと比較した場合も12倍速かった。
このAIチップ「IPU(Intelligent Processing Unit)」は拡張性が高く、IPUを4個搭載した図1のボード(1PFLOPSのIPU-M2000)を4枚重ねるIPU-POD16は、1枚ボードの4倍の4PFLOPS性能を発揮し、さらにそれを4個重ねるとさらに4倍の16PFLOPSの性能を持つラックIPU-POD64となる。これを4台接続するとさらに4倍の64P(ペタ)FLOPSとなる(図2)。

図2 IPUを拡張接続しても性能は全く落ちない 出典:Graphcore
このAIチップの最大の特長は、これまでのマルチコアアーキテクチャでは実現できなかったMIMD(Multiple Instructions Multiple Data)を使っていることだ。GPUやCPUなどのこれまでのシステムではSIMD(Single Instruction Multiple Data)アーキテクチャをベースにしており、命令セットが複雑なのでMIMD方式をとることは難しかった。
IPUプロセッサは、人間の脳に出来るだけ近いプロセッサとして、超並列のMIMDアーキテクチャを採用した。人間は同時に複数のことを考えるからだという。そこで、プロセッサの機能を機械学習のプロセスだけに、命令を演算、同期、データ交換の三つに絞ることで、MIMDを使えるようにした。
またここでは神経の伝搬を考えて高速メモリとなるSRAMを採用した。それもチップあたりのインプロセッサメモリは900MBも搭載している。図3のようにメモリの中にプロセッサのコアが散りばめられた構造をしている。IPUには独立したコアが1472個集積しており、8832個のプログラムスレッドがそれぞれ独立に動く。TSMCの7nmプロセスで製造し、チップ面積は823mm2。IPUチップの消費電力は150Wで、ヒートシンクを設けているが、冷却は空冷方式。
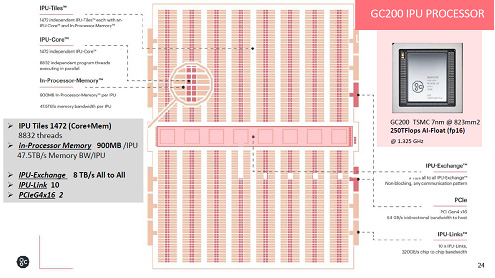
図3 インプロセッサメモリ(SRAM)を900MB集積し、1472コアを集積したIPUチップ 出典:Graphcore
分散メモリを利用したMIMD並列演算では、BSP(バルク同期並列)ソフトウエアを使って、図4のように演算する。つまり、IPU内では演算し、同期をとるとデータの遅れや進み具合がバラバラだが、データを交換し、さらに演算を進める。次にもう一つのIPUとも同期をとり、データ交換・演算を行う。
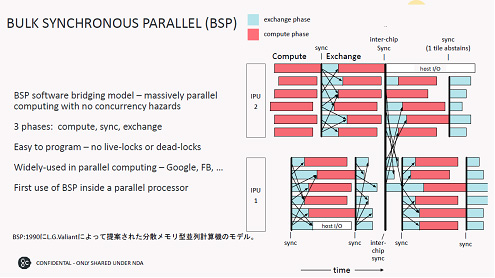
図4 演算・同期・データ交換の3つの命令で超並列を実現 IPU同士も同期をとる 出典:Graphcore
このような方式で演算、同期、データ交換を繰り返していくと、さらにIPUを追加してもどこかで必ず同期をとってデータ処理していくため、IPUを追加しても性能は落ちない。これが図2で示した、IPUを搭載したボードを大量に並列拡張できる理由だ。
IPU-M2000ボードの消費電力は900〜1100W(標準)と大きいため、用途はデータセンターやクラウド向けになる。ボード1枚で4個のIPUチップを制御するSoCはArmのCortex-AコアとFPGAからなる。ゲートウエイはIPU同士を接続するために使う。またボードにはSSDやDRAMメモリも搭載しており、IPUチップは150W/チップだが、全体では1kW前後になる。
Graphcoreの強みはチップとハードウエアの拡張性だけではない。ソフトウエア開発キットも用意しており、PytorchやTensorFlow、Onnxなど機械学習フレームワークにも対応し、GPUライブラリのCUDAに相当するようなソフトウエアスタック「Poplar-SDK」を備えている。
想定顧客はデータセンターを持つ、金融、HPC、ヘルスケア、確率統計処理などの業界になる。大きなAIモデルにも対応できることがIPUシステムの強みと言えそうだ。

