����ե��֥쥹ȾƳ�Υ٥���㡼��TRIPLE-1��AI������ȯ
���ܤˤ����������ե��֥쥹ȾƳ�Υ٥���㡼��AI���åפ���褦�ˤʤäƤ�����ʡ���Ԥ��ܼҤ��֤��ե��֥쥹ȾƳ�Τ�TRIPLE-1�ϡ��ؽ������뤳�Ȥ����ä�AI���åס�GOKU�פ�ȯ����ʿ�1�ˡ�����ü��5nm�ץ�������Ȥ�AI���åפ˽��Ѥ��륳���γ�ȯ�Τۤ����餫�ˤ�����

��1���ե��֥쥹ȾƳ�Υ٥���㡼����ȯ����AI��������ŵ��TRIPLE-1
AI���åפˤʤ�5nm�Ȥ���Ķ���ٲ����Ѥ�ɬ�פʤΤ����˥塼�����ǥ��ɽ�������MAC�黻���¿���ͤ�����еͤ�����ۤɡ��ʹ֤�Ǿ�˶�Ť��뤫������ʹ֤�Ǿ�ˤ���Ǿ�˿�ɴ�ġ���Ǿ�ˤ�1000���Ĥο��к�˦�����ʤ���˥塼������Ȥ����Ƥ��롣�������������ŵ�����Ǿ�������������Ƥ��롣���Υ˥塼���������Τ��˥塼���ͥåȥ���Ǥ��롣��ñ�̤Υ˥塼������Ѥ����Ȥ���AI���åפϤޤ��ʤ���ΤΡ���ɴ�ĤΥ˥塼������Ѥ���AIȾƳ�β�ϩ�Ϥ��Ǥ�IBM�����Ƥ��롣���������ǥ������ɽ��������˥֥��å���˽��Ѥ���˥塼����������å��߷פˤ�äƤޤ��ޤ��ʤ��ᡢ���å�������Υ˥塼������Ȥ���ɽ���Ϥ��ʤ��褦����
�˥塼���ͥåȥ���Υ�ǥ�Ǥϡ��˥塼����1�Ĥϡ�¿���ϡ�1���ϤΥѡ����ץȥ����ǥ�ǵ��Ҥ���뤳�Ȥ�¿�������Ϥϥǡ����ȽŤߤ�ä��Ʊ黻����(��2)���˥塼����1�Ĥα黻�ϡ��ǥ�����Ū��ɽ������ȡ��ǡ���1�߽Ť�1+�ǡ���2�߽Ť�2+��������+�ǡ���n�߽Ť�n���Ȥ���������ɽ������롣���ʤ����(�ݤ���)��(����)�黻��MAC: multiply accumulate calculation�ˤ�ԤäƤ��뤳�Ȥ��������롣������ʥ���Ū�ˤ�¿�������ϥǡ�����¿���νŤߤ������ɽ�����Ȥ�Ǥ��롣
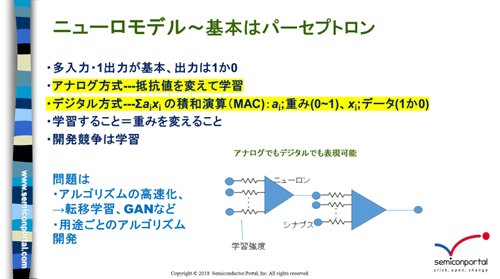
��2���˥塼���ͥåȥ����������ϩ��ɮ�Ժ���
�����ͤ�1��0�Ȥ����礬¿����¿�������ϱ黻������碌�ƽ��Ϥ�1��0��ɽ�����뤿��ˡ��黻��ʬ�ϥ��ƥå״ؿ����Ĥޤꥳ��ѥ졼���Τ褦�ˤ������ͤ��㤨��0.5����ᡢ����ʾ��1���ʲ���0��ɽ����Ϣ³�ؿ���ɽ�碌�Х��ƥå״ؿ��ϡ������⥤�ɴؿ��Ƕ���Ǥ��롣�˥塼����ο������䤻�н����˿ʹ֤�ƬǾ�˶�Ť�������������Ƴ�����������Ȥ�������ǥ˥塼����������롣
�����ǡ���ĤΥ˥塼���鼡�Υ˥塼����ؤȼ����ȥͥåȥ���������롣�����ǥ�����Ū��������ϩ��ɽ������ȡ�MAC+�����DRAM�ˤ�1�˥塼����Ȥ��ơ����β�ϩ��¿��������¤٤Ƥ������ºݤˤϥ˥塼������������ɴ���Ĥ�ñ�̤ˤޤȤᡢ���Υ֥��å���¿��������¤٤ƹԤ���Ǿ���ǥ벽���롣���������̤ξ�����MAC�Ȥ������ܹ�¤��GPU���åפˤϽ��Ѥ���Ƥ��뤿�ᡢNvidia��GPU��AI���åפȤ��ƻȤ��Ƥ�����
¿����MAC�黻�ȥ��꤫��ʤ�˥塼����֥��å������¿���¤٤뤿��ˤϤǤ���������ٲ����Ƶͤ��������ͤ���ޤʤ���С��ʹ֤�Ǿ�ˤ��Ϥ��ʤ������Τ������ٲ����Ѥ�AI���åפˤ�ɬ�פȤʤ롣
GPU��CPU�����ٲ��Ǥ�AMD��Qualcomm���ʤ�Ǥ��ꡢAMD��7nm��GPU��ȯ���Ƥ��롣���������Ծ�ˤϽФƤ��ʤ��Ȥ���������ǥǥ����ץ顼�˥Υե졼�����Ǥ���Chainer��ȯ���Ƥ����ץ�ե����ɥͥåȥ�����Ҥ�AI���åפ�2018ǯ12��Υ��ߥ���ѥ�Ǹ������������λ���12nm�ץ�������ȤäƤ���(���ͻ���1)��TRIPLE-1�����ٲ�����Ƭ��Ω�����⽸�Ѥ�AI���åפ��ܻؤ�����5nm�Υǥ������ʤ�Ƥ������ޤ���AI������2019ǯ9��˴�����������ץ�в٤�������ɾ�������
�����ɾ�������Ȥ�����16�ӥåȤ����٤ǥԡ�����ǽ1000 TFLOPS��1PFLOPS�ˤǡ����ϸ�Ψ��10 FLOPS/W��AI�������Τ�100W�Ȥʤ롣�������黻���٤�8�ӥåȤǤ�16�ӥåȤǤ��Ѥ�����褦�ˤʤäƤ���Ȥ�����
���η�̤������褦�ˡ�TRIPLE-1���������Τϡ���������ϲ������ǡ��������dzؽ���������Ǥ�������Ϥ��㤵�ϡ��ǡ���������ǽ�Ϥ�夲�뤳�Ȥ��Ǥ��롣�ǡ��������ǤϻȤ������Ϥ˸³������뤿�ᡢ�������Ϥ��������ǽ��夲�뤳�Ȥ˶쿴���Ƥ�����5nm�Ȥ������ٲ��ϡ���ǽ�佸���٤����ǤϤʤ����������Ϥκ︺�ˤ���̤����롣
��������7nm����5nm�ؤ����ٲ���ʤ��пʤ��ۤɡ��ȥ�����ΥХ�ĥ����礭���ʤꡢ��α�ޤ�ϰ����ʤ롣�����ǡ���α�ޤ�����������ϩ��Ƴ�����뤳�ȤǥХ�ĥ���������Ƥ���Ȥ������ȥ�����ΥХ�ĥ���®�٤�®�����٤���ʬ�䤷������Ƥ����Τ��Ȥ���������˴ؤ��Ƥ��õ���д�����Ȥ��Ƥ��롣
��ĤΥ�����MAC+����ˤ�����ˤ������¤٤�櫓���������ι���黻�����Ϥ�����ؤȶ�Ʊ�dz�ȯ�����Ҥ�RTL��register transfer level�ˤ�ץ������ʤ��顢���եȥ������β��ɤ�ä��Ƥ����Ȥ��Ƥ��롣AI���������������쥤�����Ȥϼ��ҤǼ�ݤ��Ƥ��ꡢȾƳ���߷ץ��˥���¿�����Ȥ����碌�Ƥ��롣�Ұ���30̾����7�䤬���˥����Ȥ�����
���ϳ�ȯ����AI���������¤٤ơ�������륵�������꤮����礭�ʥ��å�(25mm��32��)���߷פ��뤳�Ȥ���SerDes��𤷤Ƴ������̿������������ĥ�����������������³�Ǥ���褦�ˤ��롣���Τ���AI��ϩ��ʬ�����ѤϤޤ����ꤷ�Ƥ��ʤ���ǯ��ˤϥơ��ץ����Ȥ������Ȱյ�����Ǥ��롣Ʊ���¹�Ū�˿��䥷���ƥ����Ѥ��뤳�Ȥˤʤ�Ȼפ��뤬����Ǯ�߷פⳫ�Ϥ��롣
���ͻ���
1. �ץ�ե����ɥͥåȥ������AI�ؽ����åפ�鸫�� (2018/12/18)

