16nm FinFETプロセスのFPGAを量産へ
16nm FinFETプロセスがいよいよFPGAを手始めに量産が始まる。昨年出荷されたIntelの新しいプロセッサ「Broadwell」にも14nm FinFETプロセスが使われたが、生産工場がパイロット生産工場であり、量産工場ではなかった。このほどXilinxが出荷する16nm FinFETプロセスのUltraScale+ファミリ(図1)が量産チップといえそうだ。

図1 Xilinxの新FPGA、Ultrascale+アーキテクチャの製品 出典:Xilinx
Xilinxは、TSMCが製造するFinFETという3次元プロセスを駆使するトランジスタを使い、2.5Dのインターポーザによるチップ実装を採り込むことで、今回の技術を3D-on-3Dと呼んでいる。FinFETはゲート直下の空乏層を3方向から閉じこめる技術であるため、消費電力が低いことが特長となっている。ドライブ能力を上げるには、フィンの数を増やせばよい。フィンの数はW(チャンネル幅)に相当するため、フィンを増やすことでWを大きくする。
16nm FinFETプロセスで製造されるUltrascale+ファミリは、3D IC(正確にはインターポーザ上で複数のチップを並べて接続する2.5D)を利用するVirtexシリーズと、非対称マルチコアを搭載するZynqシリーズ、さらに広いメモリ帯域幅を持つKintexの3シリーズがある。この内、今回はVirtexとZynqを発表した。
16nm FinFETプロセスの性能を活かすため、最大432Mビットのメモリを集積すると同時に、SmartConnectと呼ぶ配線技術を採用した(図2)。従来、トランジスタの寸法を微細化できても配線は微細化できなかった。エレクトロマイグレーション、ストレスマイグレーションなど信頼性の問題があるからだ。このため、トランジスタの性能は上がってもLSIとしての性能は上がらないと言われていた。
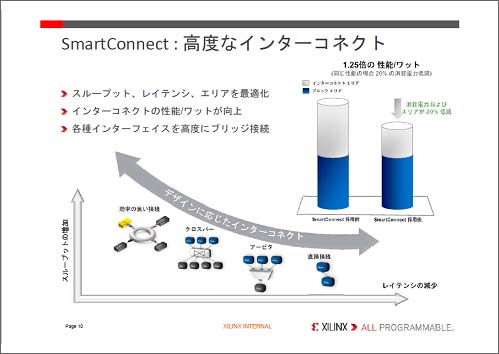
図2 レイアウトや配線によって最適化するSmartConnect技術 出典:Xilinx
Xilinxが採用した技術は、細くできない配線遅延による影響を除去するため、配線を長くせず切り替える方式のクロスバースイッチやバス競合を避けるためのアービタ、ストリームラインドパケット化など、レイアウトデザインによって配線を使い分けている。回路のスループットとレイテンシの仕様によって、どのスイッチを使うのが最適なのかを決める。インターポーザを介して2.5D実装する場合は、インターポーザにもスイッチ回路を設ける。このSmartConnectによって、同じ性能なら消費電力は20%削減されたとしている。
同社が採用したもう一つの技術はメモリの容量を増やしたことだ。FPGAダイ上では従来、並列接続された浅いFIFO(First-in First-out)メモリやシフトレジスタなど数Kビットメモリを使っていた。数百Mビット容量のメモリは外部メモリとしていた。これでは高速動作は期待できない。今回は数十Mビットの大きなメモリ(UltraRAM)をFPGAチップに集積することでメモリのヒット率が大きく上がり、レイテンシが短くなった。
さらにARMのマイクロプロセッサコアを集積したSoCシステムでは、高速のアプリケーションプロセッシングに64ビットのCortex-A53クワッドコアと、リアルタイム動作用に32ビットのCortex-R5デュアルコアを集積した(図3)ほか、グラフィックコアとしてARMのMali-400MPや、セーフティ&セキュリティ回路、メモリ、パワーマネジメント回路などを集積した。もちろんFPGA回路も集積、その中に回路ブロックとして、H.265ビデオコーデックと、高速インタフェース回路、トランシーバ回路、UltraRAMを集積した。
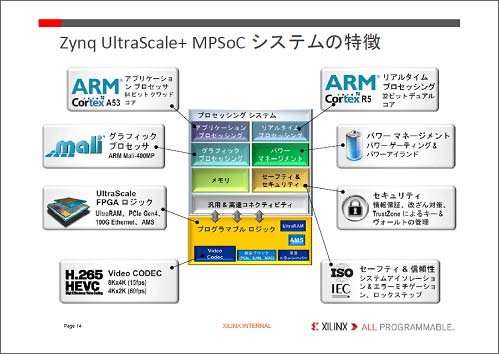
図3 ヘテロのマルチコアを集積したSoC、Zynq カスタマイズ部分のみFPGAを使う 出典:Xilinx
Xilinxは従来の28nmの7シリーズと、今回の16nm FinFET技術のSoCとを比較した。このUltraRAMとSmartConnectの両方を用いた場合、PCIeモジュールでの画像処理では同じ消費電力で性能は、従来の525Operations /秒が1880Operations /秒と3.6倍に上がった。一方で、Ultrascale+アーキテクチャを集積したMPSoCのベンチマークでは、1080pのフルHD画像を4K2Kに変換するビデオ会議の応用では、1ワット当たり5倍の性能、公共安全放送のソフトウエア無線の応用では1ワット当たり4.8倍の性能をそれぞれ得ているという。このUltrascale+アーキテクチャでは2015年に合計50本以上のデザインがテープアウトされる予定だとしている。

