ニューロAIはデータフローコンピュータに乗ってくる時代になるか
半導体チップからコンピュータラック、基盤モデルまでフルスタックでAIを提供するスタートアップ、SambaNova(サンバノバ)が日本オフィスを開設、そのチップアーキテクチャにデータフローコンピューティングを採用していることがわかった。AIの基本的なモデルであるニューラルネットワークもデータフロー方式であるため、AIとは相性が良い。古くて新しいデータフローコンピュータ時代がやってくるかもしれない。

図1 SambaNovaのCEOであるRodrigo Liang氏
データフローコンピューティングは、アイデアこそ1980年ごろにブームがあったものの、これまで実用化されてこなかった。データフローのロジックを作ることが難しく、しかもアプリケーションもなかったからだ。データフローコンピュータは、ノイマン型コンピューティングとは異なり、データの流れに沿って処理を進めていく方式。ニューロンからニューロンへの流れに沿って積和演算を進めていくニューラルネットワークの処理と似ている。
一方、従来のノイマン型コンピュータは、何番地の命令を取ってきて、何番地のデータなどを演算せよなどのプログラムに沿って演算するため、絶えず演算器とメモリ(レジスタなど)とのやり取りが欠かせない。
ところが、ここにきてデータフローコンピュータが急きょ浮上してきた。1月に開催されたRISC-V Day Tokyo 2024で、カナダのスタートアップTenstorrent社がRISC-VのCPUコアを使い、データフローアーキテクチャを次世代チップ設計に採用することを明らかにした。TenstorrentはAIと相性の良いデータフローアーキテクチャのチップを設計しており、今年中にはテープアウトを目指している。狙いは、性能を維持したまま、消費電力を下げられるとの思いからだ。
そして、シリコンバレーを拠点とするSambaNovaがデータフロー方式のAIチップを最適に設計すると、消費電力が約1/28に激減することがわかった(図2)。現在、AIチップでトップのNvidiaの最新GPUであるH100を使ったAIコンピュータ「DGX」がほぼ28台分と同じ1兆パラメータのAIソフトウエアを扱えることになる。

図2 SambaNovaのコンピュータ1ラック分で、NvidiaのH100搭載DGXコンピュータ24台とネットワークスイッチ12台や電源などの分を合わせた分と同じTCO(総運用コスト)になる。ほぼ消費電力も1/28になるという。
NvidiaのH200「Grace Hopper」では、CPUとGPUを1パッケージに搭載し、CPUで疎行列の計算を、GPUで密行列の計算をさせている。ニューラルネットワークの計算には疎行列となるa×0=0という演算が極めて多い。これをGPUだけで計算するとひたすら無駄な消費電力を食わすだけにある。そこで結果が0と分かり切っている計算はソフト的にCPUで行い、本来の計算はGPUで行う方が電力効率は高い。しかし、あくまでもフォンノイマン型の計算機アーキテクチャを踏襲しているだけであり、神経細胞(ニューロン演算器)から神経細胞へと次々と進んでいくニューラルネットワークのモデルとはやはり不自然になる。
データフローコンピューティングなら、データからデータへと流れていき、データがCPUとメモリが一体化されており、CPUから長い道のりのパスを経てメモリをアクセスしないため、ニューラルネットワークの流れと同じ仕組みになる。Nvidiaの研究者によると、64ビットの倍精度の積和演算では20pJ(ピコジュール)のエネルギーを消費するが、チップ内をデータが1mm動くのに26pJもかかるという。CPUからメモリを取りに行くのにその距離が1cmもあればその10倍の無駄なエネルギーを消費することになる。これでは従来のアーキテクチャの限界になる。
SambaNovaのもう一つの売りは、従来の生成AIのようにクラウドを利用するのではなく、セキュアなコンピュータユニットを企業向けに提供することだ。コンピュータを顧客企業にオンプレミスで設置し、SambaNovaが完全な遠隔管理を行う。企業はサブスクリプション料金を支払う。
従来の生成AIと違ってクラウドを使わなくて済むようになるのは、次のような理由によるとLiang CEOは述べている。まずオープンソースの言語モデルLlama2を企業内の各部門に展開し、それをベースに部門ごとのエキスパート知識を学習させ、さらにファインチューニングを行うだけで済むからだ。ゼロから学習させる必要はない。このデータを基に推論するため、コストは安くなる。これまでクラウドベースの生成AIから追加学習などのコストが20%、推論が80%を占めていたという。SambaNovaの方式だと推論コストを8%に下げることができるという。
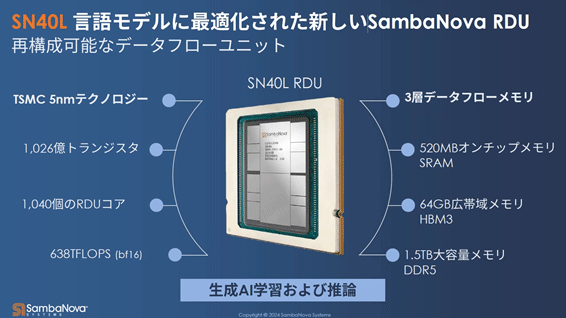
図3 SambaNovaのデータフロー方式のAIチップ 出典:SambaNova
演算するコンピュータ1ユニットは、10UサイズのコンピュータでCPU2基とRDU(AI専用チップ)を8基(12TBのメモリ含む)搭載したもので、チップ「SN40L」(図3)は、再構成可能なデータフロー方式のAIチップである。AIチップの周りに重みメモリとしてDDR5、キャッシュのようなHBMを配置しており、AI処理する前に外部メモリからデータをロードしておく。
SambaNovaの経営陣はかつてのSun Microsystems出身者が多く、コンピュータ業界のプロだ。技術的な考え方がしっかりしており、これまで適切な応用がなかったデータフローコンピュータを花開かせる企業になる可能性はある。現在シリーズD段階で11億ドルを資金調達しており、この段階でソフトバンクグループも6億ドルを出資した。ちなみにシリーズAでGoogle Venture、シリーズBでIntel Capital、シリーズCで最大ベンチャーのBlacklockが出資している。

