ニューロチップ概説 〜いよいよ半導体の出番(5-3)
いよいよ最終章の最後にやってきた。ここでは、今後の動向を中心に紹介する。GoogleやIntelがこれからどの方向に向かうのか、どのようなアルゴリズムが出てくるか、さらには半導体IC化する場合の消費電力はどうなるか、などこれまでのデータを元にこれからの方向を議論する。(セミコンポータル編集室)
著者:元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
5.3 最後に 〜今後の動向と課題〜
2016年で特に目立った点は、ビジネス面ではIntelとGoogleのハード側での充実とIoTおよびEdge系への流れである。また技術面ではモバイル化搭載を狙った圧縮技術の実用化に向けた動きである。その影響はエッジ系/IoT全般に波及する。本節ではその現状の動向を整理し、最後に課題を述べる。
現状と今後の動向
(ア) ビジネス
図53は最近のGoogle社とIntel社の動きだ。データセンター/サーバでの対応はもとより、IoT/エッジ系への流れが速い。
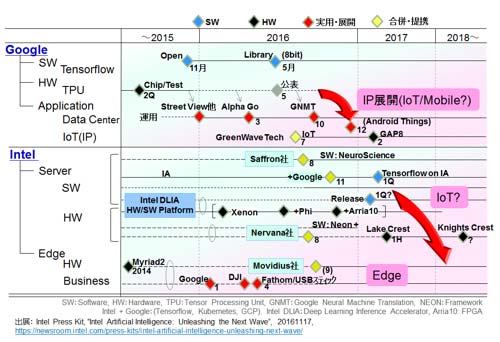
図53 Google社とIntel社の最近の動向 (Intel社情報は参考資料 113および114を参考に作成)
Googleで目を引くのは、TensorFlowを絡めたGreenWave社(GAP8)へのTPUのIP供給の可能性だ。12月のAndroid Thingsの公表(参考資料115、116)も気になる。図54に示すようにエッジ側での実行(分散実行)への移行が予想以上に速く進むかもしれない。背景には、データセンターの容量の逼迫があるのかもしれない。2020年に今の100倍の高速エンジン実現という話も聞くが遅いのかもしれない。高度なアルゴリズムの成功と実用化、ユーザの増加、そしてIoTの成長を考えるに、データセンターのハードの計算能力(速度と規模)向上はもとより、いかに実行を分散しておくかが成長の鍵となる時代が来たのかもしれない。
Intelの情報は、同社の発表(参考資料113)を元に、日経情報(参考資料114)も加味した。8月以降の3社(Saffron社/Nervana社/Movidius社)との合併(買収)の動きには驚いた。それぞれの会社がここ2年ほど目立っていたからだ。サーバ系の展開はもとより、エッジ系の強化が見られる。画像が得意なMovidius社、また2017年になって買収を表明したMobilEyeとどのようにタッグを組むのか今後の動向が気になる。
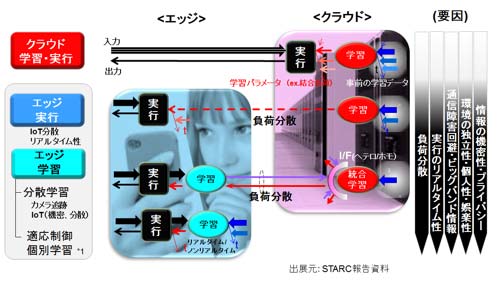
図54 クラウドからエッジへの実行・学習の分散の要因とステップ
(イ) アルゴリズム
NIPS2016(12月5日バルセロナ)の結果が気になる。6000人が参加したとのことで、盛況だったに違いない。この寄稿が出る頃にはいろいろな記事や情報が出ていると推測する。教師無し学習を中心に、教師有り学習に変わる学習、環境より予測(Prediction)する手法等々、特に自然言語関連が注目である(GNMT含めて既に発表済み?)。言語が簡単に扱えるようになると人間とのインターフェースが言葉に変わり、より身近になるからだ。リアルタイムで個人向けに人工知能を育てたくなる。まるで自分の子供のように。
(ウ) LSI技術
繰り返しになるがSRAMオンチップで図55に示すように0.1W(以下含め)で1TOPS/Wを越える大規模なディープラーニングの処理が可能になった。現在は画像中心だが、もっと低精度で次元の大きい処理が今後注目されると予想している。
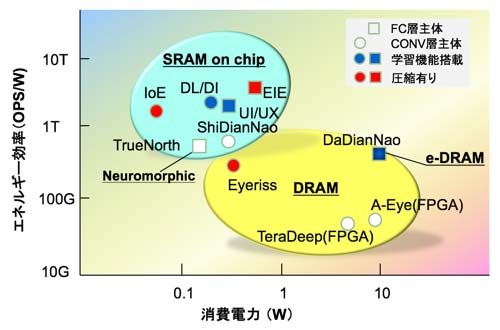
図55 エネルギー効率(エネルギー当たりの演算性能)と消費電力の関係
図56に示すように画像認識では、精度を落とした実用レベルでは、IoEのチップが実証したように、0.05W級のレベルにある(ただし、IoEは情報が少ない点、解釈には留意が必要)。Squeeze Netでも同レベルと推測される。今後、高精度化を狙ったチップが出てくる(ISSCC2017では数件の1〜10 TOPS/WのLSIの発表があった。図56に代表的なチップKU-Lueven大学のENVISIONを加えた。さらに1件Imagenetのエラー率5-10%の高精度を狙うVGGNetを扱うLSIの報告があったが処理速度が遅すぎる)。さらに時系列処理の実装例(例えば、クラシカルな物体検知手法とRNNを組み合わせた行動予測がある(参考資料119))も一層表面化してくる (ISSCC2017ではKAISTがCNN+RNNを発表)。
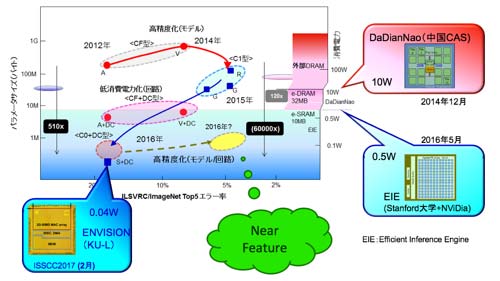
図56 LSI開発の技術トレンド 〜実装レベルで高性能化か
低消費電力に加えて、プログラム(パラメータが重たい)の総容量が100MByteを割ってくるとモバイルへの搭載が進むと言われている。携帯経由だとiOSでは100MB、アンドロイドだと50MBと言われている(参考資料117、118情報が少し古いが)。またプログラムの書換え(パラメータ更新)の頻度と時間もポイントになる。図56に示すように10MBを切ってきているので、ソフトウェアベースだが急激にスマホでの搭載が進むと考える(思った程速度は出ないが)。機械翻訳に各社・各機関が注力しているのはかなり良い線まで来ているからだ。100〜200MB位までは来ている。今後の動向は携帯の5Gの波及動向とも絡む。
最後に
今後の展開および課題を図57に示すネットワークの領域(規模:入力とパラメータ)(1)〜(4)に分けて概説する。(1)と(2)は実行、(3)と(4)は学習に関するものだ。(3)と(4)はほとんどこの寄稿では詳しく扱わなかった部分である。
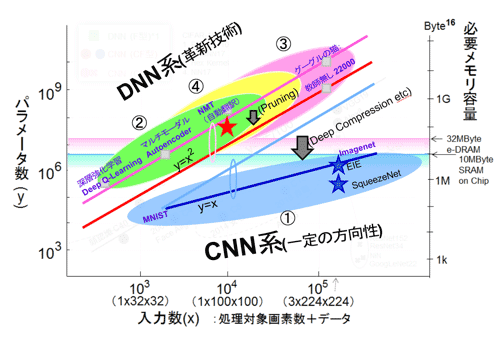
図57 LSI実装面から見た今後の方向性(CNN系とDNN系)
(1)実行(CNN/パターン認識)〜技術マッピングとフレキシビリティ
(10k〜10Mパラメータ領域:図57): CNN系に関しては、CNNをベースとするアルゴリズムの進展と展開が少し気になるが、ある一定の方向性(畳込み層の位置づけと圧縮技術)が見えてきた。単体の認識機能から複合高機能システム(例えば、 CNN→RNN 図8:https://www.semiconportal.com/archive/contribution/applications/160722-neurochip2-1.html)の前処理(前段側)の機能として広く使われるばかりでなく、その主構成となる畳込み層が極めて能力のある「層」であることから多くの新しい周辺(材質認識とか合成・生成とか・・・)技術・応用領域を切り開いてゆくと想定できる。応用別(複合機能化・システム化含め)に、実装技術を圧縮技術およびフレキシビリティを軸にマッピングすることがポイントと考える。
(2)実行(DNN/時系列)〜入力次元数が鍵、応用により圧縮・メモリ/デバイスが重要に!
(1M〜100Mパラメータ領域):DNN系(非CNN系)に関しては実行・および学習共に技術革新が必要な領域である。アルゴリズムはもとより、LSI実装の観点から材料、デバイス、回路技術、および回路アーキテクチャとがんばりが必要だ。代表的なネットワークは時系列処理のRNNと強化学習だ。特に実装の観点から、入力の次元数には注意が必要だ。符号化された情報(例えばNMTだと分散表現、行動推測だとR-CNNを前段に持つ)がRNNの入力となっている点だ。ここでも応用分野と技術のマッピングが必要だ。
(3)学習(DNN系/ある程度完璧)〜アルゴリズムが完全に固まっていないのか?!
(100M〜1Gパラメータ領域):現在実用化されている学習の多くが教師有り学習だ。教師有り学習では、教科書作りが必要だ。ビッグデータ(自動運転のための道路情報とか)になればなるほど気の遠くなるほどの作業が発生すると聞いている。例えば100万枚の写真を1000クラスに分類するのは実は人間で、人間が「巧み」の技を教科書にまとめ上げる(単なる1000のクラス分けだが)だけでくたくたになる。(余談だがImageNetの人間のエラー率5.1%だって怪しい)。教師無し学習が待望されている。AlexNetが出なければもしかしたら教師無し学習が寄り道せずに進化していたかもしれないとも聞く。LSI実装というよりもっと上位のアルゴリズムの段階の課題である。不勉強で動きがあることは感じているが詳細は掴んでいない。今後動向を知る必要がある課題と考えている。
(4)DNN系/学習〜(少しずつ学習)そろそろ動き出しそうな気配がある!
((3)の領域より下と思われる):もう一つはある程度のリアルタイム性と個別対応が可能な学習だ。学習当初は間違っていても良いのかもしれない。これも人間の動作に近いことから多くの研究がなされている。より知的な側面も感じられ魅力的な分野である。
上記の(3)と(4)の学習にさらには第1章1.6節で簡単に述べた環境の学習(Prediction)を含めて3つの学習の体系化(NIPS2016の理解含め)と推進が今後重要になると考える。
謝辞
今回の寄稿にあたり、お声を掛けていただいたセミコンポータルの皆様、また所属していた際に支援を頂いた旧(株)半導体理工学研究センター(STARC:2016年5月末で解散)の皆様には感謝致します。さらに、情報の基礎となる技術また考え方等をご指導・ご教授いただきました大学・研究機関・企業の皆様、特に北海道大学の浅井哲也教授の暖かいご指導には心より感謝致します。
著者のあとがき
当初、第1章を書き始めた2016年の春から夏にかけての段階ではディープラーニングが適用されるアプリケーションに関し紙面をより割く予定でしたが、夏から秋にかけ回路関係のまとめに入った段階で予想以上に圧縮技術の台頭が激しく、一定のレベルでまとめた方が良いと考えました。個人的な環境の変化もあり、当初より時間がかかってしまいました。アプリケーションに関しては、特に(1)と(2)の「実行」ではアプリケーションの探索というより実装のフェーズに入ったと考えます。(3)と(4)の「学習」に関しては、逆にアプリケーションの開拓も並行して今後ますます重要になると考えています。今回は割愛させていただきます(今後何らかの機会があれば紹介したいと思います)。
最後に、第1章1.6節の図5を用いて説明致しましたが、人工知能に対し我々が考え期待しているレベルの知能に対して、大体2〜3合目まで来たというのが個人的な印象です。今後は、ディープラーニングに匹敵する大きな谷がもう一つ二つはあるはずで、その達成のためには材料からデバイス技術含めて半導体の寄与すべき点は極めて大きいと考えます。遠く及びませんが(ほんの1合目)、その推進の一助と本寄稿がなれば幸いと考えている次第です。
編集注)百瀬氏の現在の肩書は、北海道大学 大学院情報科学研究科 学術研究員である。
参考資料 (1〜104までは前回以前)
- IBM Synapse PJT リーダ Dharmendra S Modha氏のブログ (2015年8月17日) IBMの開発状況.
- 電子情報 Quartz, "IBM has built a digital rat brain that could power tomorrow's smartphones", IBMのボード情報, 2015年8月18日.
- IBM Synapse PJT リーダ Dharmendra S Modha氏のブログ (2015年8月3日), "Brain-inspired Computing Boot Camp Begins", IBMのブートキャンプ.
- Alexander Andreopoulos, Rodrigo Alvarez-Icaza, Andrew S. Cassidy and Myron D. Flickner, "A low-power neurosynaptic implementation of Local Binary Patterns for texture analysis", 2016 International Joint Conference on Neural Networks (IJCNN), 最近のTrueNorth 低消費関連の論文、2016年11月2日.
- Caroline Vespi (IBM), "Deep learning inference possible in embedded systems thanks to TrueNorth", IBM Research Blog, September 21, 2016, Posted in: Cognitive Computing, IBM Research-Almaden, IBM 新しい成果のアピール(参考資料44の内容)、2016年9月21日
- Steven K. Esser +, IBM参考資料44の最終版の発表、Proceedings of the National Academy of Sciences of the United States of America, vol. 113, no. 41、 2016年10月11日.
- Steven K. Esser +, "Algorithms1/2", 学習のアルゴリズムの詳細、2016年10月11日に公開.
- 米国 DeepScale社, ホームページ, Squeeze Netの著者のForrest N. Iandola氏が所属.
- Intel社のIntel Press Kit, "Intel Artificial Intelligence: Unleashing the Next Wave", 20161117, Press Kit Intel社のAI戦略のプレス発表.
- 日経テクノロジーオンライン, "エッジからクラウドまで握る、IntelがAI戦略を発表", 2016年11月18日、Intel社のAI戦略
- Android Thingのページ; "Build connected devices for a wide variety of consumer, retail, and industrial applications", Google Android Thingsのページ, 2016年12月13日
- Wayne Piekarsk, "Announcing updates to Google's Internet of Things platform: Android Things and Weave", Google Android Developers Blog, 2016年12月13日, GoogleのAndroid Things
- アピアリーズTech Blog, "アプリの容量に制限はあるの?", 2015年6月11日、スマホのアプリ容量の制限.
- ブログ, "Apple、2GBから4GBへiOSアプリの容量上限を変更!", 2015年, スマホ容量
- Kyuho J. Lee, Kyeongryeol Bong, Changhyeon Kim, Jaeeun Jang, Hyunki Kim, Jihee Lee, Kyoung-Rog Lee, Gyeonghoon Kim, Hoi-Jun Yoo, "14.2 A 502GOPS and 0.984mW Dual-Mode ADAS SoC with RNN-FIS Engine for Intention Prediction in Automotive Black-Box System", 2016 IEEE International Solid-State Circuits Conference, 14.2 pp.256, 2016年2月, KAIST RNN/ADAS
- Jun Sawada, Filipp Akopyan, Andrew S. Cassidy, Brian Taba, Michael V. Debole, Pallab Datta, Rodrigo Alvarez-Icaza, Arnon Amir, John V. Arthur, Alexander Andreopoulos, Rathinakumar Appuswamy, Heinz Baier, Davis Barch, David J. Berg, Carmelo di Nolfo, Steven K. Esser, Myron Flickner, Thomas A. Horvath, Bryan L. Jackson, Jeff Kusnitz, Scott Lekuch, Michael Mastro, Timothy Melano, Paul A. Merolla, Steven E. Millman, Tapan K. Nayak, Norm Pass, Hartmut E. Penner, William P. Risk, Kai Schleupen, Benjamin Shaw, Hayley Wu, Brian Giera, Adam T. Moody, Nathan Mundhenk, Brian C. Van Essen, Eric X. Wang, David P. Widemann, Qing Wu, William E. Murphy, Jamie K. Infantolino, James A. Ross, Dale R. Shires, Manuel M. Vindiola, Raju Namburu, and Dharmendra S. Modha, "TrueNorth Ecosystem for Brain-Inspired Computing: Scalable Systems, Software, and Applications", SC16, Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis Article No. 12, 2016年11月13日, IBMのTrueNorth活動(EcoSystem)

