ニューロチップ概説 〜いよいよ半導体の出番(2-2)
第2章:ディープ・ニューラルネットワークのニューロチップへの実装〜その勘所は!!
第2章では、ニューラルネットワークの代表的な技術としてCNN(畳み込みニューラルネットワーク)をまず紹介し、ディープ・ニューラルネットワークの全容を解説した(ニューロチップ概説〜いよいよ半導体の出番(2-1)参照。この第2章の2-2では、それを受けてCNNのモデルの進化を紹介し、半導体チップに落とすための勘所を解説する。(セミコンポータル編集室)
著者: 元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
2.4 CNNのモデルの進化 (1) 〜アーキテクチャの変遷:より広く?! より深く 152層〜
2012年にトロント大学が発表したAlex Netから、2015年12月に開催された機械学習分野における最高峰の国際会議と言われているNIPS(the Annual Conference on Neural Information Processing Systems 2015)にてMSRA(Microsoft Research Asia)が発表したResNet (Residual Net)までのいくつかの代表的なCNNのモデルに関して説明する。モデルは断りのない限り、国際的な画像認識のコンペティションであるILSVRC/Imagenetが主催するベンチマークの一つの一般物体認識部門に参加し優秀な結果(1位、VGGNetは2位)を示したモデルを採り上げる。
2.4節ではそれらのアーキテクチャ(構成)を、2.5節では内部の構成要素を、そして2.6節ではLSIへの実装において重要な積和演算回数とパラメータ数に着目して説明する。最後の2.6節でモバイルへ搭載した際のケーススタディを加える。それらの理解を通して各モデルをLSIへ実装する際の勘所をつかむのがこの章の主旨である。
(1) 代表的CNNモデル
CNNをベースとして、画像の認識率の向上を目指しいくつものモデルが提案されてきた。根底にあるトレンドはネットワークの層をより多く積み重ねることによる向上である(なお、多層が有利だというある程度の基礎的な理解は進んでいる(参考資料14、171頁))。図9に代表的モデルの推移を示す。1998年に最初に発表されたCNNの育て(生みの)親と言われているLeCun氏の考案したLeNet6(番号は層数:参考資料24)を参考として加えた。AlexNet8、VGGNet19(参考資料25)、ResNet152(参考資料28)まである。層数が6層から152層まで増加(よりディープに)している。ワイドになっているモデルもある(GoogLeNet22:参考資料27)。シンガポール国立大学が2014年始めに発表したNiN (Network in Network:参考資料26)のモデルも加えてある。
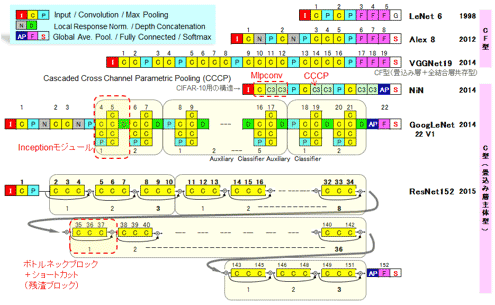
図9 CNNの代表的なモデル: CF型(共存型)からC型(畳み込み層主体型)へ
図9の見方に関しては、基本要素からなるAlexNetを用いて説明する。ここでは、I-C-N-P-C-N- 中略 -F-F-F-Sと並べられている。Iは入力Image、CはConv層、Nは正規化関数(Normalization)、PはPooling層、Fは全結合層(Fully Connected layer)、そして最後のSは活性化関数のSoftmaxである。なお、Conv層の直後にある活性化関数は省略されているので注意が必要である。ReLU (Rectified Linear Unit)がAlexNet以降全てのモデルの全てのConv層の直後で使用されている。
多層化による精度向上の追求の流れの中でネットワークの構成に2つの変化が現れた。2013年末〜2014年初頭に発表されたシンガポール国立大学のNiN(Network in Network、参考資料26)が先鞭をつけた。なお、図9に示したNiNの構成は、CIFAR-10用(別のベンチマーク)である。ここで、図の右端で区分けしているように、従来の全結合層が複数層入っているものを、CF型(畳み込み層+全結合層共存型)と呼び、NiN以降の畳み込み層に主体が置かれ、かつConv層がモジュール化しているモデルをC型(畳み込み層主体型)と呼ぶこととする。C型は単純なConv層ではなく、モジュール化されていることが特徴である。
(2) C型の特徴(その1)・・・モジュールの導入
CF型からC型への1つ目の変化は畳み込み層(C)の構成が複雑になった点だ。従来のVGGNetまでの単純に畳み込み層がC-CもしくはC-C-C-Cと繰り返される形式から、それぞれの意図を持ちながらモジュール形式(図9のMlpconv/NiN、Inceptionモジュール/GoogLeNet、残渣ブロック/ResNet)に置き換わり、そのモジュール自体がネット内で繰り返される(詳細は、参考資料26〜29の各論文、参考資料14、もしくは米Purdue大学の教授でかつTeraDeep CTOのCulurciello教授のブログ:Neural Network Architectures(参考資料32)を参照)。
図10が各モジュールの詳細構造である。簡略化した説明になるが、計算量/パラメータ数の単純増加を抑えるテクニックを入れつつ特徴表現力を上げたMlpconvモジュール(NiN:Conv層の直後に単純な全結合のCCCP層[Cascaded Cross Channel Parametric Pooling]をいくつか挿入)、NiNのテクニックを取り込み加えて畳み込み層を並列にし認識率アップを目論んだモジュール(Inception Layer/GoogLeNet)、そして両者の良い所を取捨選択し、かつ直結した100層以上で学習を可能とする残渣ブロック(Residual block/ResNet)の3つのモジュールが各々のモデルで提案された。残渣ブロックにより新しい概念の残渣学習(Residual learning)が可能となる。これらのモジュールにより多層化が可能となり、認識率も向上する。詳細は次節で述べる。
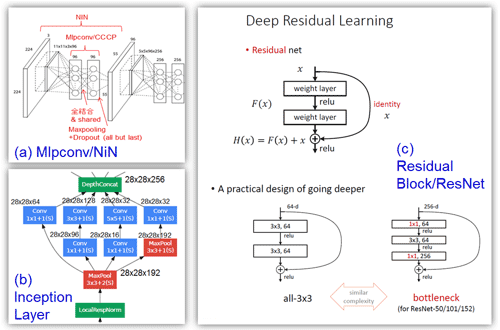
図10:各モジュールの構造
(a) Mlpconv/NiN(参考資料26) 赤字は著者追記、(b) Inception Layer/GoogLeNet (参考資料27)
(c) Residual net/ResNet (参考資料28)。
(3) C型の特徴(その2)・・・全結合層が極度に軽くなる
2つ目の変化は、前段の特徴抽出部の最終端に多数の特徴マップ間を単純に平均化するGAP (Global Average Pooing:全体プーリング) 層が導入され、さらに後段部の全結合層の数が3層から1層と少なくなっている点である。前段の特徴抽出部に高い特徴表現力が備わったことから後段部の負担が軽くなった結果と考えられている。すなわち、全結合層のクラス化の作業が、前段部の特徴抽出の作業に織り込まれた結果、全結合層が不要となったと考えられる。なお、GoogLeNet、ResNetの後段部に全結合層が1層入っているが、これは転移学習を容易とするためとGoogLeNetの開発者、Szegedy氏は述べている (参考資料27、14)。
2.5 CNNのモデルの進化 (2) 〜構成要素の勘所: ポイントは5、6カ所〜
本節では、モデルの進化を構成要素の視点から切り込む。表1に前節で述べた各モデルの数値(上段)、および構成要素の一覧を示した。
(1) 演算回数・パラメータ数、そしてエラー率
一般物体認識のエラー率に関しては、当初の発表に、その後の改良値も加え併記した。ResNet34のエラー値「+1.5%」はResNet152に対する相対増加分である。層数、パラメータ、演算数は2.3節で述べた方法で計算した結果である。パラメータ数と演算数はモデル側の発表値および参考資料6、14の結果等と合っていることを確認している。ResNetのパラメータ数は現時点で公開されていない。NiN、GoogLeNet以降で数値に大きな変化がある。詳しくは、次節で述べる。
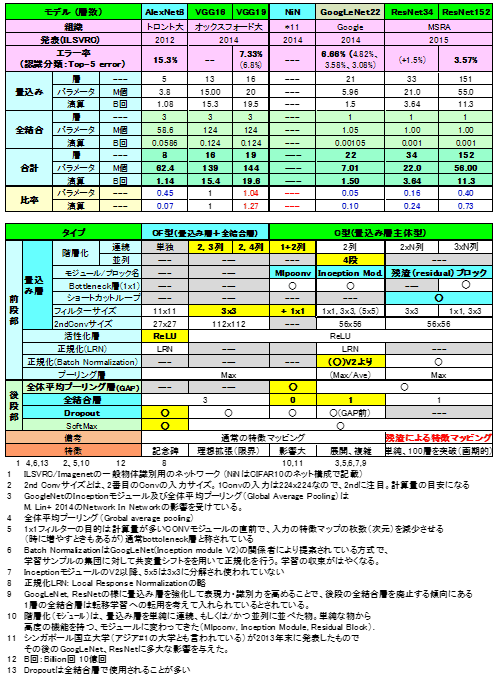
表1 CNNの各ネットモデルの構成一覧
(2) 構成要素
表1の下段に各ネットモデルの構成要素の一覧を示した。前節に習い、CF型(畳み込み層+全結合層共存型)とC型(畳み込み層主体型)に分けている。
表の黄色い箇所が、各構成要素が最初に導入・提案されたモデルを示している。推移を読み取るとAlexNetで大枠のネット構成の骨子(畳み込み層、活性化関数 ReLU、Softmax、学習方法Dropout)が固まり、引き続き認識率改善をターゲットとしてVGGNetでConv層の多層化追求と小型フィルタへのシフトが行われ、その後NiN以降、Conv層内のモジュール化へと流れてきていると見ることができる。各々の説明は、表1の脚注に記載した。重複をさけ説明は割愛する。
表2にCNN構成のための勘所をまとめた。活性化関数、学習時・技法はC型/CF型に共通だが、それ以外はC型主体でまとめた。大方は、固まってきたと考えられる。複雑なのはConv層モジュールで、今後どのように変わるか注視すべきである。
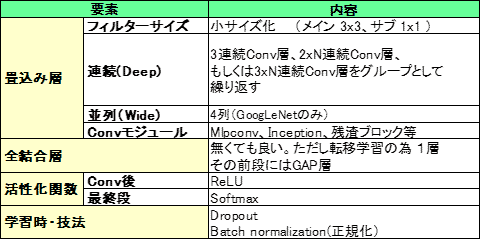
表2:CNNの構成の勘所 C型主体 (活性化関数、学習時の技法は、C/CF型共通)
(3) 小型フィルタへのシフトとモジュール化
当初のAlexで使用された大型の11x11に代わり3x3の小型フィルタが使われる理由に、演算回数が少なくなる点がある。以下のように説明ができる。9x9の領域に畳み込みを掛ける場合9x9のフィルタだと(9x9)x(9x9)=81x81回の演算が必要である。3x3のフィルタだと(3x3)x(3x3)の演算を9x9の領域にすなわち9回行わないといけない。総数は(3x3)x(3x3)x(3x3)=81x9回。全体では3x3のフィルタだと演算量は1/9と減る。よってまずフィルタを小さくしてそれから認識率の改善を狙う。
減らした分を何かで補償しようとすると、ディープ化かワイド化か、もしくはマップ数を増やすかである(小型フィルタの他の効果もあることが前提)。NiN以降のConv層のモジュール化も根っこはフィルタの小サイズ化による影響への対応策と考えるとわかりやすい。その折衷案的なものがGoogLeNetで、1x1、3x3と5x5 (Version3では5x5は廃止)を並列に入れている。すなわち小型フィルタ化の影響解消のためにワイド化を追求したと考えると、ある程度は意図をつかめる。一方、ResNetは単純にDeep化を追求し、学習が収束しないこと/認識率が悪化することから残渣学習(residual learning)の新概念を導入した。なお、Convモジュールの中に共通して使用されている技法にBottleneck層がある。特徴マップ数を自在に変化させる技法である。例えばRGBの3色で分けていたが、より中間色の8色に特徴マップを分ける。またその逆をやる、といったイメージである。 1x1のフィルタはそのマップ数調整/整合取りのために多用されている。
2.6 CNNのモデルの進化 (3) 〜演算数とパラ-メータ数:34層位で良いのではないか⁈〜
本節では、各モデルを、LSIの実装に直結するパラメータと演算数の観点から切り込む。
(1) CF型とC型の傾向
図11に前節の表1で示した各ネットワークモデルの層数(9層から152層)に対する、ILSVRC/ImageNetでのエラー率(棒グラフと曲線:右軸)、および各モデルのパラメータ数(点線)と演算回数(実線:ニューラルネットワークの演算回数はほとんどが積和演算数/MAC数であり、またMAC数はネットワークの層と層をつなぐ接続数と等しい)の推移をプロットした。右軸、左軸および下辺の層数を含め全て対数軸となっている。AlexNet8とVGGNet19は赤(CF型)で、またGoogLeNet22/ResNet152(C型)は青で表記した。エラー率に参考値としてResNet34とResNet50の値を加えた。VGGNetのVersion4で、3.08%の報告があるが、プロットしていない(参考資料30)。
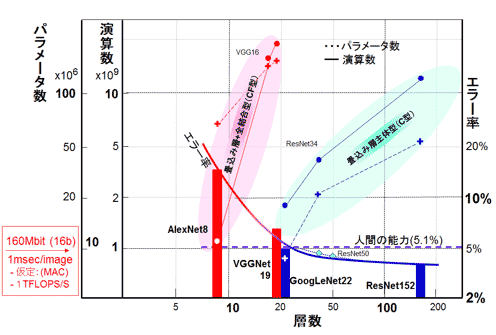
図11 演算数とパラメータの関係
(2) CF型では限界
AlexNetの8層からVGGNetの19層に増加すると、エラー率は16.4%から7.3%へと改善された。しかし、パラメータ数は6200万個から1.44億個と2倍増、演算数は11.4億回数から196億回と約20倍上昇した。これ以上の改善を狙うとパラメータ数と特に演算数の増加が当然予想される。また学習が収束しないと言われている。さらに図12に示すように多層にすると(20層から56層に増やすと)エラー率が悪化するというデータが報告されている(参考資料28/29:MSRAのHe氏の論文)。
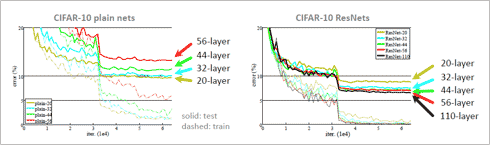
図12 多層化によるエラー率増大(CIFAR-10)参考資料28/29:
横軸 学習回数、縦軸 エラー率(%) 左図 従来型(ResNetのShort Cut無)は劣化している。
右図 ResNetは改善されている。
(3) C型でブレークスルー
その壁をブレークし(壁と認識する前に解決されてしまったようだ)より多層化を可能としたモジュール/モデルの代表が、前節で説明したMlpconv/NiN (Network in Network) Inception Layer/GoogLeNetと、さらにResidual Block/ResNetである。なお、GoogLeNetの層数は22層である。実際にはワイド(2あるいは4並列の部分もあり)になっていることからConv層を全てカウントに入れると40層(図9でカウント)となる。ResNetはResidual Blockの導入により152層でも学習が可能となった。エラー率は、GoogLeNetは6.67% (後に、4.82%/BN-V2、3.58%/V3、3.08%/V4とVersion Up)、ResNetは3.57%と共に人間の能力(5.1%:少し怪しい基準だが)を越える結果を叩き出した。
C型のもう一つ重要な点は、図11の20層当たりでのVGGNet19とGoogLeNet22の数値の差である。パラメータ数が1.44億個から701万個に、演算回数は196億回から15億回と各々一桁以上(20分の1)改善されている点である。 16bit演算とすると、GoogLeNetだと、112Mbit、ResNet34だと352Mbitのメモリが必要となる。余裕をもって混載するレベルではないが、かなり扱いやすいレベルのメモリ量の範疇に入ったと考え得る。
(4) C型は層数に比例して増加
簡単な定量的な説明をする。図11は対数グラフである。パラメータ、演算数共に層数にほぼ比例している。以下の関係を持つ。
- 層数に比例 演算数 1億回/層、パラメータ数 50万個/層
- パラメータ数/演算数の比 1/200〜1/300程度 (入力が224x224、クラス1000の場合)
パラメータ数が少ないのは、共通のパラメータを使用している(重み共有:weight sharing:参考資料6)からで、その比(繰り返し使われる回数)は各層の出力のサイズの平均値に近いはず。両モデルとも各層の出力のユニット数は14x14=256を前後にしたサイズである。この200〜300の値に対する原理的な説明(理解)は現時点ではできない(たぶん、入力とクラス数と関連する)。
(5) 多層化の追求 1202層まで しかし!
MSRAのHe氏らはCIFAR-10という一般物体認識のベンチマークでResNetの1202層までトライした(参考資料28)。学習は可能だが7.93%とエラー率は悪化した。110層が試した中ではベスト6.43%と報告されている。劣化原因に関しては、CIFAR-10の規模が小さい(32x32ピクセルRGB 、10クラス)ことから、過学習/過適合(Overfitting)が起こっているとの推測が報告されている。驚きなのは小さな32x32クラスの入力画像でも極めると110層も必要な点である(参考資料28、7頁)。
まとめると、従来の「畳み込み層+全結合層型:CF型」からモジュール化した「畳み込み層主体型:C型」に移り、100層以上の多層での学習が可能となった。その結果、人間の能力を超えた3%台(ILSVRC/Imagenetのベンチマーク)のエラー率に到達した。さらにパラメータ数(メモリ量)及び演算数(演算時間、高速性)も一桁(以上)の軽減が実現された。アプリケーションとのエラー許容範囲との見合いだが、34層でもかなり良いレベルである。エッジ応用で実装が手に届くところまで来たと考え得る。
(6) 注目は、GoogLeNetと ResNetでどちらが良いのか?
MSRAのHe氏らの提案のResNetの残渣学習という斬新なアイディアに対する評価は高い。またResNetは昨年末各種のコンペティションで最高値を獲得している。その中で物体認識より難易度が高い物体検知のFaster R-CNNのアルゴリズムをResNet上に実装し、検知率で最高値を叩き出している点は特筆すべきである。なお、このアルゴリズムのオリジナルもMSRAのHe氏のグループの発案である。最近、別機関がRecurrent NNにResNet適用した、など多くの展開の報告もある(参考資料29)。余談であるが、MSRAのKaming He氏は5月末MSRAを退職し、今月7月にFacebookに転職した。別に、物体検知のR-CNNおよびFast R-CNNで著名なR. Girshickも昨年11月にMSからFacebookに転職した。今後、一層Facebook AI research (FAIR) の所長でCNNの育て(生みの)の親のLeCunさんの鼻息が荒くなると予想される。またFacebook(ResNet??)とGoogle(GoogLeNet)の一騎打ちが一層激しくなると予想される?!
一方、Google側は2016年2月に”Inception-V4, Inception-ResNet and the Impact of Residual Connections on Learning”なるタイトルの論文でGoogLeNet V4(version4:参考資料30)を発表している。GoogLeNetにResidual Learningを取り入れたモデルである。物体認識率(エラー率)は、3.08%を達成している。ただし、この発表に対して構造が複雑すぎるという意見もある。
かなりまとまりつつあるが、しばらく注視が必要と考える。
参考資料 (1〜23までは前回以前)
24. Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition”, Proceedings of the IEEE, 86(11):2278–2324, November 1998, LeNet.
25. Karen Simonyan and Andrew Zisserman, “Very Deep Convolutional Networks for large-Scale Image Recognition”, in International Conference on Learning Representations (ICLR2015), 20150507. VGGNet
26. Min Lin, Qiang Chen, Shuicheng Yan, “Network In Network”, 2014年3月4日(Ver3). NiN.
27. Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, “Going Deeper with Convolutions”, 2014年9月17日. GoogLeNet V1.
28. Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, “Deep Residual Learning for Image Recognition”, 2015年12月10日. ResNet.
29. Kaming He, “Deep Residual Networks, Deep Learning Gets Way Deeper”, ICML 2016 tutorial, 0160619, 最新のResNet情報
30. Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning”, 2016年2月23日. GoogLeNet V4.
31. Sergey Ioffe, Christian Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”, 2015年3月2日(V3). GoogLeNet V2. w/BN (Batch Normalizationの論文)
32. Eugenio Culurciello, “Neural Network Architectures”, ブログ, 2016年6月4日, Neural Network Architectureのサマリ.

