人工知能への道(6)〜生成AIブームの意味する所
昨年来、生成AIに関する報道が活発化している(注1)。 ニューラルネットワークの大規模化によって、翻訳、文章生成、静止画、動画、音楽等のコンテンツ生成が人間並みになったとの評価が多いが、AIの能力がそのように高度となった背景には、深層ニューラルネットワーク技術とニューラルネットワーク探索技術、または進化的計算とのアイデア融合があると考えられる。 回路アーキテクチャの開発が自動化されることの社会や産業に及ぼすインパクトは計り知れないほど大きく、今後の動向には目が離せない。
大波の正体: 深層学習とニューラルネットワーク探索技術の融合
この数ヵ月は、ニューラルネットワークの次のブームが到来したと思えるほどである。Microsoft社がOpenAI社に約100億ドルを投資する旨の報道があり(参考資料1)、それに呼応するように、Google社はネット検索技術とBARDと呼ぶ会話型AIの統合を発表した(参考資料2)。「生成AI(ジェネレーティブAI)の大波がやってくる」との解説もある(参考資料3)。
研究論文の件数にて動向からは、2018年以降、Self-Attention、Neural Architecture Searchといった用語の使用頻度が急増中であることが分っていた(図1)。 翻訳用ニューラルネットワーク回路の構造用語として、AttentionやTransformerという言葉(注2)が増えており、進化的計算(Evolutionary Computation)や遺伝子アルゴリズム(Genetic Algorithms)などと呼ばれる「種の進化を模倣するアルゴリズム」に関する研究も、依然高い件数を維持していた。
特に注目したのは、Neural Architecture Search (ネットワーク探索)と呼ばれる「学習情報に適合するニューラルネットワーク回路のトポロジーを自動探索する技術」である。 「種の進化を模倣するアルゴリズム」と「ニューラルネットワーク技術」の融合は、歴史的に予想されていた展開だったからである。
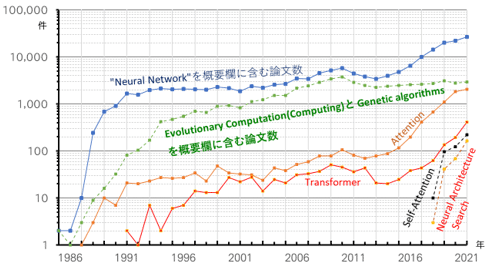
図1 IEEEが集計するニューラルネットワーク関連の論数の推移(論文の概要欄に、各キーワードが載る件数をカウントしている。近年、AttentionやTransformerに関連する論文が急増しているが、Neural Architecture Searchに関する論文数の興隆も始まっている) 出典:Web上でサービスされているIEEE Xploreを用いて、2022年年初に筆者が作成。
深層学習(Deep Learning)は、多段のニューラルネットワーク回路の重みパラメータを学習データによって最適化する自動化技術であるが、ニューラルネットワークの回路トポロジーや、使われる活性化関数、ハイパーパラメータ等は、人間が介在して試行錯誤を繰り返しマニュアル設定する必要があった。
これに対して、ネットワーク探索技術は、ニューラルネットワークの回路トポロジーを自動生成することを目指していた。 回路トポロジーの最適化が自動化できるのであれば、活性化関数やハイパーパラメータの最適化も自動化可能と見て良いだろう。そのような自動化技術が汎用技術のレベルに向上すると、様々な産業へのAI採用を画期的に促進するインパクトを持ちうる。
以下、OpenAI社のKenneth Stanley 氏の2002年の論文(参考資料4)と、Autodesk AI LabのAdam Gaier氏の2019年の論文(参考資料5)の内容を参考にしながら、深層ニューラルネットワークにおける深層学習とネットワーク探索技術が融合しつつあるとみる筆者の見解を紹介したい。
ボールドウィン効果
今から約100年前、米国の心理学者であるジェームズ・マーク・ボールドウィン氏(1861-1934)は、「後天的学習によって獲得されていた形質も,次第に遺伝的に獲得され先天的能力に転化する」との説を提示した(参考資料6)。そして、その仮説は、トロント大学のGeoffrey Hinton氏らの計算機シミュレーションによって、1987年に確認されていた(参考資料7)。
深層学習の創始者であるGeoffrey Hinton氏は、深層学習技術の研究を推し進めた当初から、進化的計算(Evolutionary Computation)や遺伝子アルゴリズム(Genetic Algorithms)をニューラルネットワーク技術開発の観点から重視していたというのは驚きである(注3)。
ボールドウィン効果は、ニューラルネットワーク回路の用語で表現すると、「ランダムに変異しうるネットワークトポロジー(回路アーキテクチャと同義)を学習データによって選別すると、その回路アーキテクチャは改良される」となる。
1993年に、当時英エディンバラ大学の数学科教授であったニック・ラドクリフ氏は、「Connectivity(神経細胞間の結線の最適化)とWeights(シナプス結合パラメータの最適化)を組み合わせた統合化スキームはこの分野の聖杯といえる」と、両技術の融合を求めていた(参考資料8)。
これらの逸話が、今日の「大波発生」の布石となって来たのではないだろうか?
深層学習技術とニューラルネットワーク探索技術の対比
改めて、ニューラルネットワーク探索技術を深層学習技術と対比してみたい。
多層ニューラルネットワークは、深層学習(Deep Learning)技術によって脳内神経細胞の後天的学習プロセスを模倣(エミュレーション)しようとする試みであったのに対し、ニューラルネットワーク探索技術は、「種」の進化の過程で進む「先天的な神経回路構造の進化」を模倣しようとする(表1)。
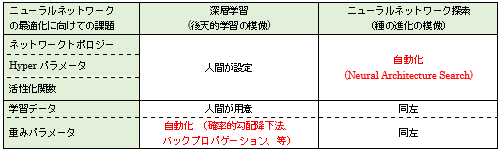
表1 Deep Neural Networkへの深層学習技術とニューラルネットワーク探索技術の対比 (深層学習技術では、そのネットワークトポロジー、ハイパーパラメータ、活性化関数をエンジニアの経験を元に設定する必要があるが、ニューラルネットワーク探索では、それらの最適化を自動化する。) 出典:参考資料4と5を元に筆者が作成。
深層学習は、誤差情報逆伝搬法(Back Propagation、BP)と確率的勾配降下法 (Stochastic Gradient Descent、SGD)というパラメータ最適化のための手法を得て開花したが、それらで行う計算の特徴は以下であった。
・ ニューロンの演算対象(入力情報)は、ベクトルや行列とする。
(ベクトルや行列の成分値は、多くの場合、0から1の間の小数点値)
・ 演算では、ベクトルと行列間の積算や和算、およびベクトル成分値の微分(差分の除算)を用いる。
・ フィードバック(再帰)型のアルゴリズムを含み、計算を反復することがある。
・ 必要に応じて(非線形処理を行わない場合)、演算の出力値を「確率値」と解釈する。
深層ニューラルネットワーク回路の要素回路である単層分の回路は、集積回路でしばしば現れるデコーダ回路の構成に似ている(図2)。集積回路のデコーダ回路を構成する論理演算子(AND、OR、等)を、ニューロンモデルに置き換わったような構造を取るが、ニューロンモデルの出力値は、一般的には、”0“と“1“の間の数値を出力するとされ、その値を「確率値」と解釈するのである。
もちろん現在の集積回路の論理ゲートを駆使して、小数点演算や確率演算を行えるし、「確率を出力する回路」を構成することもできる。 だが、ニューラルネットワーク回路の動作を追う時、論理自体が確率的になったとみなす方が分かり易く、恐らくそのように解釈した方が数学表現との対応を取りやすくなる。
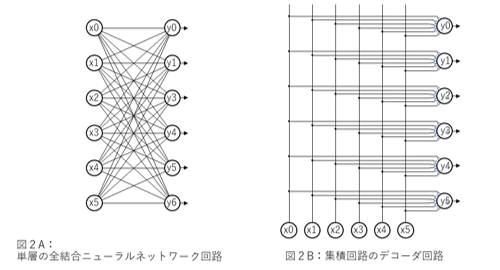
図2 単層のニューラルネットワーク回路と、集積回路でしばしば現れるデコーダ回路の比較 ニューラルネットワーク回路は、論理演算子(NAND、NOR、等)からなる組み合わせ論理回路を、ニューロンモデル回路に置き換わったような構造を取る。 出典:筆者が作成
そもそも、「論理」には2種類あるともいえるだろう。
一つは、数値計算にて使われる「論理」であり、それは、現在の集積回路の論理ゲート(AND、OR、等)からなる論理回路を組み合わせて構成するのが適切であり、1ビットの値は“0”もしくは“1”の2値である。 数値計算にて使われる「論理」は、コンピュータやネットワークを発達させて来た。
もう一つは、言語で表現される「論理」である。「真」を“1”に、「偽」を“0”に対応させることがもっともらしいが、一般に言語表現では、真とも偽ともつかない内容が多く、本質的にファジー(確率的)な状態表現を多用して表現した方が分かりやすい。言語表現の処理には、確率的論理のプロセスを表現するニューラルネットワーク回路が向くのである。
現在進行中と言われるAI革命(参考資料9)は、言語表現の演算を効率的に行う「ファジーな論理」をエミュレーションする回路プラットフォームの第1世代アーキテクチャが見いだされた段階と言えるのではないかと筆者は思う。
その回路プラットフォームを用いてアーキテクチャ探索に相当する演算を効率的に行うには、以下の要件が満たされる必要がある。
・ ネットワークトポロジー情報のランダムな改変(値の擾乱操作)が容易なこと
・ 試行結果を収集(集合化)が容易なこと
・ 収集結果の評価と選別が容易なこと
ところで、ニューラルネットワーク回路のアーキテクチャの探索では、フィードバック(再帰)型のアルゴリズムを用いない。 種の進化はフィードバック(再帰)しないからである。 しかし、ランダムな改変(値の擾乱操作)を非常に多くの試行し、評価を行うため、探索時の計算量は膨大となる。 更に、選別されたネットワーク回路のトポロジーは、後天的な学習に相当するプロセスにて調整される必要があるだろう。
但し、そのような動作を具体的に考えようとすると大きな問題があった。ニューラルネットのアーキテクチャ探索を行うネットワーク空間(もしくはプラットフォーム)をどのように定義し、表現し、設定するかは自明ではなかったのである。
Transformer技術はニューラルネットワーク探索用の探索空間を提供した
生成AIのニューラルネットワーク規模は、2020年以来、驚くほど巨大化した。500GBを超えるパラメータを有するモデルも相次いで発表されている(参考資料9)が、筆者は、「この巨大化は、ニューラルネットワーク探索用のプラットフォームとして必要な大きさであった」と見る。
いずれのモデルにおいても導入されているAttention機構(参考資料10、11)は、そのネットワーク結線を使うか使わないかのゲート機能を有しており、ネットワーク構造の進化を模倣表現するスイッチ回路として適切だったからである。
Attention機構を備えた大規模ネットワークは、遺伝子の変異を模倣するためのパラメータ空間を提供した。 パラメータ空間が大きい方が、より多くの進化を探索できる。だからこそ巨大化すべきだったといえる。
次に、ネットワーク探索と生成AIの深層学習の関係を定めなくてはいけない。シームレスに行えるのかもしれないが、教師無し学習と教師有り学習で両者を使い分けることも考えられる。「種の進化」を模倣する先天的学習後には、ネットワーク中の不要な枝葉を剪定し、簡略化してから、後天的学習のプロセスを開始するという扱いも可能だろう。 また、後天的学習のプロセスを行った後に、再度、不要な枝葉を剪定、簡略化を行うということも考えられるし、後天的学習のプロセスを行った後の「生成AI」としてのコンテンツ出力後に追加の学習を行うということも考えられる。
ニューラルネットのアーキテクチャ探索を行う汎用プラットフォーム回路は今後ハードウエア化する
生成AI用ニューラルネットワークの大躍進の扉を開いたのは、2017年にGoogle社が発表したTransformer技術であるといわれている(参考資料11)。 2020年以降、巨大化を開始した生成AI用ニューラルネットワークは、翻訳や文章生成に続いて、静止画生成、動画生成、音楽生成にて実用化寸前の状況に辿り着いている。
更には、コンピュータプログラム作成や、数学問題の証明のような科学技術の探求サポートなどの分野での応用が期待されている(参考資料9)。
筆者は、今後、以下の観点での動向に注目しようと思う。
・ 生成AI改良の次のステップ
(異種の生成能力への対応、Multi-Modal化、汎用化だろう)
・ ニューラルネットワーク探索可能なプラットフォームの専用ハードウエア化
(確率的論理の表現に適した回路を用いた全体回路のアーキテクチャはどのようになるのか?)
・ 集積回路の設計能力への応用
ニューラルネットのアーキテクチャの探索が、人間よりも良い回路を設計(探索)し、より良い設計図面を生成する技術となる時、その回路プラットフォームを用いた生成AIが社会や産業に及ぼす影響は計り知れないほどに大きいと、筆者は思う。
注
1. 生成AIとは、比較的少ない言語列を入力として、各種の文章や、静止画、動画、音楽、コンピュータプログラム等のコンテンツを非常に高速に出力するニューラルネットワーク回路の技術をいう。予め大量の文章を使って、単語間に見出される前後関係確率や関連性確率を学習した生成モデル(参考資料13)を抽出し、ニューラルネットワークに保持させている。 注目度の高いOpenAI社のChatGPTは、更に、「人間の指導」ともいえるトレーニングを行い、より違和感の少ないコンテンツを出力するようにしている(参考資料12)。
2. Attention機構は、米国ServiceNow社のBahdanau氏らが2015年の論文(参考資料11)で提示した単語や図形情報間の関連性の強さを学習したデータを元に、入力された文章や画像の注目部分や文脈等の全体像を動的に学習し、ニューラルネットワークの処理の進展を制御する機構。
Google社のVasmani氏らは、2017年に、Attention機構の制御するエンコーダ-デコーダタイプの文章翻訳用ニューラルネットワークを論じ、そのアーキテクチャをTransformerと呼んだ(参考資料10)。 TransformerのAttention機構は、ニューラルネットワークの前段層が出力した情報の中の注目すべき情報を通過させ、注目すべきでない情報を堰き止めるようなゲート的制御を行う。
3. 筆者は、「トポロジー(回路アーキテクチャ)をコンピュータシミュレーションによって進化させる技術が現実のものとなろうとしている」ことを知り愕然とした。 集積回路のアーキテクチャも生成AIから出力する可能性があると思えたからである。
参考資料
1. 「マイクロソフト、オープンAIへの最大100億ドル投資で協議」、Bloomberg (2023/01/10)
2. 「次なるテクノロジーの波はメタバースではない。ジェネレーティブAIの大波がやってくる」、Wired (2023/01/26)
3. 「グーグルも会話型AIと検索を統合へ。ChatGPT対抗の詳細は発表会で明らかに?」、Wired (2023/02/08)
4. Stanley, K.O. and Miikkulainen, R., “Evolving neural networks through augmenting topologies”, (2002)
5. Gaier, A. and Ha, D., “Weight Agnostic Neural Networks”, (2019)
6. Baldwin, M.J., “A New Factor in Evolution”, (Jun 1896)
7. Hinton, G. E. and Nowlan, S. J., “How learning can guide evolution”, (1987)
8. Radcliffe, N.J., “Genetic set recombination and its application to neural network topology optimization”, (1933)
9. Thompson, A.D., “Integrated AI: The sky is infinite (2022 AI retrospective)”, (2022)
10. Vaswani, A., et al., “Attention Is All You Need”, (2017)
11. Bahdanau, D., et al., “Attention-Based Models for Speech Recognition”, (2015)
12. OpenAI社のホームページの記事, “Aligning Language Models to Follow Instructions”,
Aligning Language Models to Follow Instructions (openai.com)
13. 岡島義憲、「人工知能への道(4);対話する構造」、セミコンポータル (2021/10/07)

