日本のスパコン富岳はArmコアベースで世界一の性能を獲得
スーパーコンピュータの性能ランキングとして6月でのTOP500が発表され、日本のスパコン「富岳」がトップを獲得、415PFLOPSのLINPACK性能を示した。CPUそのものは富士通の設計だが、CPUコアにはArmv8.2-A SVE(Scalable Vector Extension)アーキテクチャが使われている。Armの命令セットを使い、メモリをCPUに可能な限り近づけると共に、CPU同士のネットワークには富士通が開発した「TofuインターコネクトD」を採用した。
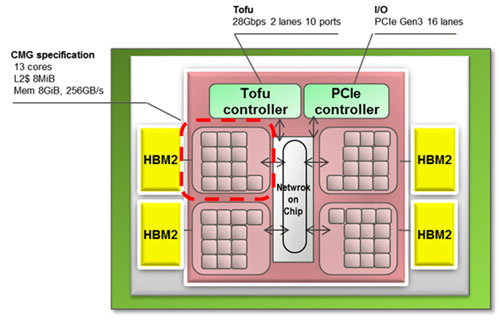
図1 CPU1個の内部構成 出典:富士通
日本のスパコンがトップになったのは8年半ぶり。当時の「京」では富士通のCPUアーキテクチャSPARC64を使ったが、今回はArmの64ビットCPUコアを52個、1チップに集積している。チップ全体を4つのブロックに分け、1ブロック内に演算コアを12個、制御用アシスタントコアを1個とL1/L2キャッシュを集積している。
CPUコアとメモリをできるだけ近づけることでチップ内の計算速度を上げ、ブロック間をNIC(Network in Chip)スイッチで接続することでブロック間の遅延を短縮した。各ブロックは大容量メモリHBM2で接続し、大量のデータを1024 GB/sという超高速でアクセスする。
さらにこの1パッケージのCPUを1筐体に384個搭載し、CPU同士をTofuインターコネクトで接続する。富岳のシステムは396台の筐体ずらりと並べたもの(図2)となっている。

図2 今回の富岳ではスパコンの筐体を396台動作させた 出典:理化学研究所、富士通
CPU1個は、TSMCの7nm FinFETプロセスで製造し、87億8600万トランジスタが集積されている。パッケージされたICの信号ピンは594ピン。
ArmのSVEは、ベクトル演算可能で、最大512ビット幅のSIMD(Single Instruction Multiple Data)データで演算する。
また、機械学習やディープラーニングの学習も推論も可能なように、16ビット浮動小数点演算FP16や8ビット整数演算INT8などの推論演算も可能なように、データ幅を変えられる構成になっている。それも推論では精度を8ビットに落とし、消費電力の削減を図っている。
演算を最優先するスパコンは、これまでCPUが性能を決めるとしてSPARCチップをはじめ独自開発を日本では推進してきたが、Armベースのアーキテクチャでも最高性能が得られることがわかった。ArmのISA(命令セットアーキテクチャ)を使いながら、SVEというベクトル演算を拡張・追加することで、演算に集中できるようにした。要はメモリとCPUとの距離をできるだけ短くし、CPU同士をつなぐ配線を単なるバス方式ではなく、スイッチ方式で切り替えることで性能を上げられることも最近わかってきている。さらにメモリバス幅もこれまではボトルネックだったため、これもフレキシブルに拡張する方法へと変わった。こういった一連のテクノロジーは、CPU一辺倒だったこれまでの考えを改める良い機会になったといえそうだ。
参考資料
1. Japan Captures TOP500 Crown with Arm-Powered Supercomputer (2020/06/22)

