ニューロチップ概説 〜いよいよ半導体の出番(4-3)
ニューロチップの代表例として、(4-3)では圧縮技術を用いたチップの開発例として、Googleが開発したニューロチップTPU(Tensor Processing Unit)、およびStanford大学を中心に研究されている圧縮技術Deep Compressionを紹介する。圧縮は、量子化ビット数を32ビットなどから16ビットあるは8ビットに削減する技術で、ニューロチップの電力効率を上げるもの。少々長いが、チップ化には必要な技術である。(セミコンポータル編集室)
著者:元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
4.3 代表的チップ(圧縮技術を用いたチップ)〜疎圧縮、量子化そしてロスレス
本節で扱うデータおよび重みの圧縮技術は実行用だ。共通の認識は「学習時には誤差逆伝播法の重みを微調する際に精度を要し多ビットが必要」という点だ。精度劣化に関しても小さめで0.5%程度までである(この許容範囲は適用のアプリの仕様に大きく依存するはず)。
本節の(1)でGoogle社のASICであるTPUに関連する技術を、(2)と(3)でStanford大学を中心としたDeep Compressionに関する一連の技術を説明する。なお前者はデータセンタからモバイルはもとよりIoT (エッジ)までの展開を狙い、後者はモバイル(エッジ)対応の究極(?!)を狙っている。そして、最後に(4)で他のチップ(IoE等:4.1節で説明)の圧縮技術も含めて全体を概観する。なお、圧縮技術にはBinary Connect/Binarized Neural Networkといったバイナリでの学習・実行処理を探求する動向もあるが、本寄稿では割愛した。またTPUに関しては、2017年4月にGoogleよりTPUに関しての詳細な紹介、及び論文が出たのでそちらを参照してほしい。以下のブログより論文のダウンロードが可能(https://cloudplatform.googleblog.com/2017/04/quantifying-the-performance-of-the-TPU-our-first-machine-learning-chip.html)。
図35はここ1年でのGoogleとStanford大学を中心とした2つの動きを時系列でまとめたものだ。圧縮処理の方法からLSI実装(GoogleはASICを開発・使用中)、実応用へと急激に展開しているのが見て取れる。特に特徴的なのは、NMT(Neural Machine Translation:RNNベースのニューラル機械翻訳)を標的として研究・開発が急である点だ。全結合層を主体として数百メガバイト(1ギガ)級のサイズのネットワークモデルである。近い将来、スマホで自動翻訳がスタンドアローンでできるようになる勢いだ。日本語をスマホに話しかけると、スマホが中国語をしゃべってくれるのも間近かもしれない。
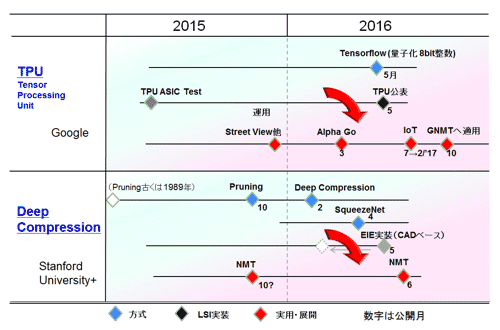
図35 圧縮技術の開発の2つの流れ(狙うはモバイル/エッジ応用)
(1)TPU (Tensor Processing Unit) Google社〜データセンタからエッジへ
図35に示すように、TPUは、2016年5月18日にGoogleのブログで発表(参考資料94、95)された。2014年本格開発着手、2015年春にはチップを、そして22日で実効的に使えるようになったとのことだ。データサーバで使われる実行用の専用ASICチップである。実際にRankBrain/Street View/Alpha Go等に使用されたとのことだ(図36)。
Alpha Goに使用されたいわゆる人工知能が右のラックだ。GoogleのTensorflowのライブラリ上で動くことが前提である。内部はデータ・重み共に8ビットで演算、エネルギー効率が1桁(10倍)改善された。ハードウェアの詳細は不明だ。32ビット浮動小数点演算を、8ビットで演算しているなら演算回数が1/4に減少(速度)、1演算当たりのメモリアクセス負荷が1/4に削減する事からエネルギー効率が10倍程度向上する。(上述の論文では、相対比較だが対CPU/GPUの速度比15〜30倍、エネルギー効率30〜80倍と報告されている)。なお、入出力部分は32ビット浮動小数点のまま扱えるのがポイントである。

図36 TPUが実装されたボード(左)、データセンタでの実行状況(ラックに搭載:右図) Alpha Goで使用されたサーバラック(碁盤の絵が貼り付けられている)
(写真は参考資料94 Google Cloud Platform Blogより転載)
GoogleユーザーのAI使用量(実行)の指数関数的な伸びへの対抗策と見てとれる(3〜4倍のユーザーを相手にできる)。またパワー低減によるデータセンタの維持コスト低減にも繋がる(メインテナンスを含めたコストメリットは10倍)。Googleのビジネス成長のための戦略エンジンと見ることができる。逆に見るならば、その性能向上の鈍化はAIの発展・成長への律速要因となる。またユーザーは無意識のうちにその恩恵(回答が早いなりAIも賢くなったと感ずる)を受ける。
ただし3〜4倍のスピードアップでは1〜2年しか持たない。エッジ側で実行の処理をしないと早々にデータセンタはパンクする。特に自動翻訳の性能が上がり、皆が本格的に使い出したらたまったものではない(今はまだまだ未成熟で原語で読まざるを得ない)。
一方、アルゴリズム、もしくはプログラム研究者、開発者にとってのメリットも大きい。なぜなら学習は精度が必要なことから32ビット程度の浮動小数点の使用が現状避けられない。その32ビットのコードをGoogleに渡し、TPU上で動作させると4倍速く動作できる。TPUから話はずれるが、固定の重み(パラメータ)も1/4となることから、モバイルへの展開(通常100MB以下がモバイルへの搭載許可のリミットと聞いている)、すなわちGoogle Play上での高度のAIプログラム実装を推進する原動力ともなる。この点からも次なるGoogleの戦略が伺える。
図35に示すように、5月以降のGoogle関連の情報を拾ってみると、2016年7月にTPUをIPコアとしてベンチャー企業であるフランスのGreenWaves Technologiesに提供している(参考資料98)。ターゲットは世界最初の本格IoTチップだ(名称:GAP8 12 GOPS、20mW 2017年2月チップ)。前述したが、TPUをグーグルのニューラル機械翻訳(GNMT:Google Neural Machine Translation:参考資料99, 100)にも適用して既に運用しているとのことだ。Stanford大学でも同様の動き(参考資料72, 73)をしており、機械翻訳(音声認識も同様)はAI関連で最もホットな領域だ。
量子化技術(Quantization)〜演算スピードアップの単純な手法
ハードウェアに関しては情報が公開されていないが、では一体どのように8ビットに量子化するのかが知りたい点である。2016年5月18日のTPUの発表に先立つこと2週間前の5月3日にGoogleのPete Warden氏のブログにTensorFlow上で動作する量子化のコードおよびその解説記事が公開されていた(参考資料96)。かなり汎用性(だれでも簡単に使えトラブルの少ない)のある圧縮技術と考える。なお、このPete Warden氏は、元JetPec社のCTOで携帯用画像認識ソフト(Apple Storeに掲載:Deep Brief Network:DBNベース)を売り出した矢先、2014年夏にGoogleに会社が買収された経歴を持つ(参考資料97)。上記のTPUの開発着手と同じ時期だ。
図37に量子化のフローを示す。参考資料96の図をまとめた。32ビット浮動小数点演算を、内部のみ8ビットの固定整数方式でデータ/重み共に計算する。重み(Weight)は事前にオフラインで計算してもよいはずだ。問題は、実データ(入力特徴マップ、出力特徴マップの各値)をどのように処理するかである。図では活性化関数(Rectified Linear関数/ランプ関数:ReLu)を例として使用した。その8ビットでのReLu演算の前にデータを32ビットから8ビットに変換する。
変換の方法は、入力の32ビットデータ内のMaxとMinの間を256に分割して、線形に0-255 (8ビットの整数表現に変換)で割り付ける。なおこの線形に割り付ける手法はDeep Compression(参考資料45)で使用されている手法と同じである。ReLuを8ビットで演算した後、非量子化を行う。右側の図は多層の途中過程を削除しスリム化したものである。もちろん、量子化が出来ていない演算があればその部分は32ビット浮動小数点で演算するとのことだ。
課題はちょっとした誤差が発生する点のようだ。量子化の際の丸め誤差である。詳細はLibrary(参考資料96、Blog参照)を読み理解する必要がある。Stanford大学およびUC BerkleyのDeep Compression部隊との議論があった(参考資料96のコメント投稿欄)。Pete Warden氏の意見は、Deep Compressionは演算量が多すぎるとのことであった。
技術的にはシンプルだが、導入の背景(データセンタの演算量の指数関数的な増加)と判断理由(ともかく処理時間の短縮)が興味深い。全体の動きを見ているとTensorFlowの範囲という縛りを与えながら、エッジ/IoTへの実行処理移行を加速化させるという戦略が浮き出てくる。TPUはLSIもしくはIPとしてその戦略コアとして位置づけられると見ることもできる。
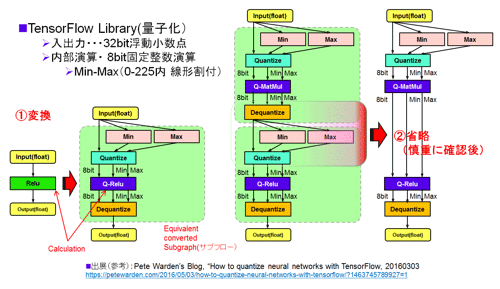
図37 データ量子化の手順 (Pete Warden氏のBlog(参考資料96)を参考に作成した)
(2)Deep Compression (Stanford大学など) 〜各要素技術〜
図35に示すように、Stanford大学のSon Han氏らの一連の発表(参考資料101、45、46)をベースとして、UC Berkleyのメンバーが加わり、行った最新のネットワークモデルSqueeze Netへの適用、さらにはStanford大学の機械翻訳の専門家たちとの共同開発であるNMT(Neural Machine Translation:ニューラル機械翻訳)への適用と、かなり大がかりに研究開発が行われてきた。
本項では、二つの論文を扱う。一つ目は2015年10月に発表、Pruningに関して扱った論文、二つ目は、量子化およびハフマン符号化を含めたDeep Compressionを網羅的に扱った本命の論文である。
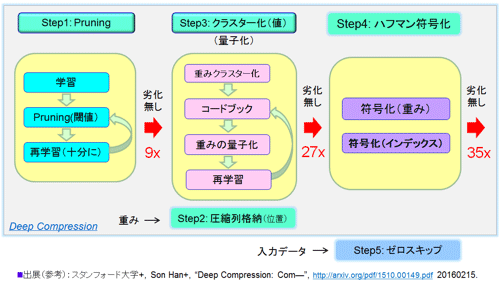
図38 Deep Compressionの圧縮のステップ (参考資料45を参考にして作成)
論文(参考資料45)を参考にして図38を作成した。Deep Compressionは3つのPruning、クラスタ化(量子化)、およびハフマン符号化(ロスレス)からなる圧縮技術の総称だ。クラスタ化は量子化と言われているが、Google社のTPUで使用しているものと技術内容は異なる。また図38に示すように実際には、Pruning後の残った重みの位置情報を圧縮する圧縮列格納方式(CSC:Compressed Sparse Column)、さらには入力データに対して行うゼロスキップがある(データの圧縮に関してはこの技術のみを用いている)。なお、ゼロスキップはEyerissが実装しているものと狙いは同様である。
手順を示すようStep1〜Step5を付記した。この5つのStepのうち、Pruningとクラスタ化は精度の劣化の可能性があるが、それ以外はロスレスで本来精度への影響は無い。なお、Pruningおよびクラスタ化では劣化が起こらない範囲での圧縮を行っている(劣化は0.4%以下)。
(ア)Pruning技術 (参考資料101)
日本語に訳すと、「枝おとし」とか「剪定」とかぴったりの名前があるが、どうも技術用語としてはいまひとつなのでそのまま、Pruningを使用する。重みの圧縮は
(1)重みの量(数)・・・Pruning
(2)重みの位置情報・・・圧縮列格納方式
(3)重みのビット数(量子化/クラスター化)・・・クラスタ化
の三つの情報量をいかに圧縮するかにある。重みの量を減らし、重みのビット数を絞る。しかし、弊害として (2)の重みの位置情報が必要となる。枝を落として圧縮するが、どこの枝を残したのかを覚えておく必要がある。本技術では、専用のメモリ(疎マトリクス)を用意している。SRAMだ。
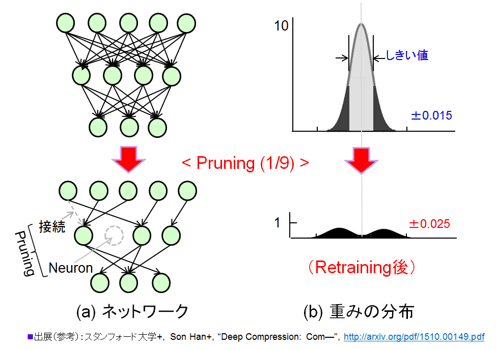
図39 Pruning技術の説明 (a) ネットワーク、 (b) 重みの分布の変化
参考資料101を参考に作成
Pruningの手順(参考資料101)
図39(a)のネットワークの図のように、不要な「枝/接続」をそぎ落とし、「ニューロン」を削除する。その対象となるのは図39(b)に示す不要なものである。図(b)も論文を参考に作成した。上側の図が最初の学習により得た重みの分布を示す。この場合は±0.015の間にほとんどのものが入っている。Pruningの対象は、重みの値が小さいものである。なぜなら、値が小さいので次段への影響が少ないからである。Deep Compressionでは「しきい値」を設定して容赦なくPruningする。また重みが全てゼロの時、もしくは出力値がゼロの時ニューロン自体も削除する。しきい値の設定の方法には独自の手法が入っているらしい。あまり明確に書かれていない(各層毎にPruningをするとか、全パラメータをどの様に分割するかの手法らしい)。
削除した後、再学習を繰り返す。学習レートを1/10に落として丁寧に行う。びっくりしないようにゆっくりやるので時間が掛かる。削除した後の重みの分布を(b)の下側の図に示した。その数は1/9となった。分布は初期状態より広がりを持つ。プラス・マイナスの2つの正規分布の形になっている点が興味深い。抑制性、興奮性シナプスを連想させる。
さて、この技術のオリジンは30年前に遡る。参考資料102,103, 104にあるように、1990年前後に確立した技術のリバイバルである。特にYann LeCun氏(参考資料103)により、かなり丁寧に検討されている。再学習、またかなり時間の掛かる点、効果が1/8である点等、既に約30年前に報告されている。さらに一歩踏み込み、エラー関数の2次微分値を最少にする重みを削除する手法(ある意味BP法に考え方が近い)を用いている。CNNの論文発表の9年前である。LeCun氏はご存じのように現在もディープラーニングの世界をリードされている方なのである種の感動を覚える。
しきい値を大きくすると圧縮率は上がり、逆にエラー率も増加する。大規模なネットワーク(AlexNet/VGGNetのImagenet/ILSVRC)でエラー率の悪化が大きくても0.4%程度と極めて小さい点に押さえている。彼らの最大と判断した圧縮率は1/9である。8/9は不要な演算だった。後述するクラスタリング(量子化)含めてどの程度類似のタスクに展開できるか(転移学習に使える)はまだ知る限り報告はない。ニューラル機械翻訳(NMT)への応用例は後述する。
位置情報の圧縮(圧縮列格納方式:CSC Compressed Sparse Column)
前述したように、しきい値によりそぎ落とした接続(枝)の位置を覚えておく必要がある。彼らが一番力を入れている点だ。図40(a)の重みマトリクスで覚えておく。マトリクスを一列の情報列に置き換え、そぎ落とした接続をゼロと見なす。さらに全体にゼロが多いことから「圧縮列格納方式」を用いてマトリクス情報を圧縮する。灰色のゼロは存在だけをカウントして位置情報を圧縮する。図(a)の下側に示した表記だ。この表記のために4ビットが必要となる。15個ゼロが連なることを考えるとそうなる。結果、Pruningで生き残った重みは4ビットの位置情報(Index)を持つ。以上がPruningの手順と内容である。これをハードウェアに実装した。
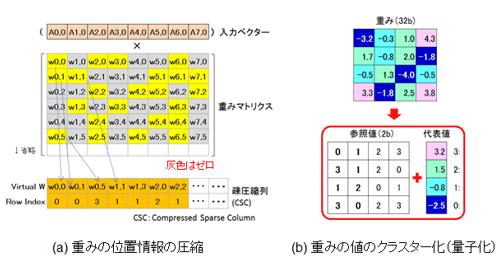
図40 (a) 重みの位置情報の圧縮、 (b) 重みの値のクラスタ化(量子化)
参考資料45を参考に作成
(イ)重みのクラスタ化(量子化)
重みの位置は圧縮したので、今度は値の圧縮だ。Deep Compressionでは、各層ごとに重みをK平均法によりクラスタリングしている。図40(b)に示すように、重みをクラスタリングし、グループ番号が重みに替わる。実際の値はグループの代表値(Centroid:32ビット)になる。学習は図40(b)に示した代表値に対して、バックプロパゲーション法による学習を反映させることにより行う。なお、この代表値の学習時の初期値は最大、最小値に対して均一に設定される。この単純なクラスタリング法だが、彼らが苦労した点だと推察する。
(ウ)ハフマン符号化
Deep Compressionでは、ハフマン符号化を用いている。ロスレスの圧縮技術である。本節での説明は割愛する(参照資料45)。
(エ)ゼロスキップ
図40(a)の入力ベクターと重みマトリクスのマトリクス・ベクター演算の際に、入力ベクター値の要素ゼロの場合はその部分の演算をスキップすする。Eyerissでは50%程度の圧縮の効果があったが、EIEの場合には、事前にPruningが行われていることから効果は少ないと推測している。全体回路構成全般に検知システムを実装しないといけないようでかなり重たい技術だ。ちなみにEyerissでは、単純に各PE内でデータを検知しているだけのようだ。
以上、Deep Compressionの各圧縮のStep 1〜5(図38)を濃淡はあるが、説明した。
引き続き、複数の論文全体を参考にしてまとめた結果を示す。
図41で、圧縮のフロー(a)と各ステップでの圧縮の効果の流れ(b)を説明する。データに関してはベクトル演算をする際に、ゼロであればスキップする。重みに関しては、Pruningにより重みの数が9分の1になった後に、そのゼロ以外の重みの位置情報に関しては圧縮列格納方式を適用する。4ビットの位置情報(Sparse Indexes)に集約される。オーバーヘッドは16%となる。重みに関してはクラスタリングで量子化を行う。
32ビットから畳込み層(Conv)は8ビットに圧縮、全結合層(FC)は5ビットにそれぞれクラスタ化される。8ビットは256種類に分けられ、5ビットは32種類に分けられたことになる。平均は(b)に示したように5.4ビットとなる。同時に256種類かつ32種類の合計288種類32ビットの代表(Centroid)の重みをコードブックとして持つ。AlexNetの場合、そのオーバーヘッドは0.1%と極めて小さい。その後、ハフマン符号化を経て、重みは平均4ビットで表現され、位置情報は3.2ビットで表現されるようになる。最後の実際の演算では、逆符号化等を行い積和の演算を行う。
なお、注意してほしい点は、図41(a)の符号化の部分は、学習の段階でオフラインで行っておく作業である。実行では、逆符号化とデータのゼロ値の検出が主なEIEの作業となる。
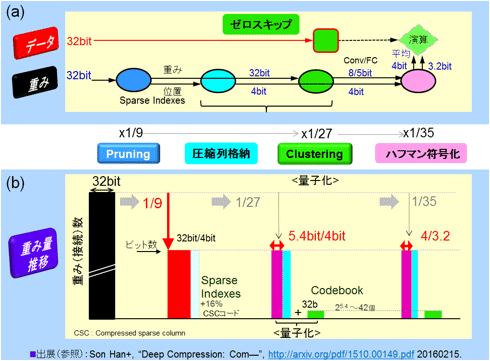
図41 Deep Compressionでの圧縮の流れ (参考資料45を参考に作成)
(3)EIE (Energy Efficient Inference Engine:Stanford大学)〜モバイル適用を狙う
前項に引き続き、Deep Compression関連である。LSIへの実装(CADレベル)したものが何度も説明しているEIE(Energy Efficient Inference Engine:参考資料46)である。
彼らはEIEの実装では、以下に示す点で内容を微調整したり、論文の内容を変えている。
1.ハフマン符号化(逆符号化)は含まれていない。
2.全体のビット数は16ビット固定小数点が出発点。
3.データにゼロスキップを入れている(圧縮率は3倍と大きい)。
4.全結合に重きを置いている(RNN/LSTM、自然言語への展開等)。
5.逆符号化と、データのゼロ値の検出により、実行が行われる。
6.他のLSI事例との比較/汎用品(GPU/CPU)を加えた。
LSIとしての機能は、Pruning、クラスタ化(量子化)の逆符号化と、ゼロ値の検出と、そしてニューラルネットワークの通常の実行である。特別な回路の実装が必要だ。逆符号化回路等を導入しないと、100 GOPS程度の性能だが、導入すると3TOPSと30倍の速度改善が得られる。通常のCPU/GPUで実行すると、その速度改善は3倍程度と記されている。ハードウェアで専用化することから一桁性能が上がることになる。回路的にはハフマン符号化(逆符号化)への対応は入れていない。理由は不明である。基準となるビット数は32ビットではなく、16ビットまで下げている。事前に検証して劣化がないと判断しての16ビットの採用だ。8ビットは劣化が激しかった。
計算の手順は以下となる。データ(Activation)の非ゼロ検出を行う。中心の制御ユニット(Central Control Unit)で64個の演算ユニットPE (Processing Element)に非ゼロ値の演算を分配している。ひまそうな演算ユニットPEに演算をさせるように制御している。その際に、入力データの値とデータの位置(index)をペアで送信する。位置情報を元に対応する重みの値と今度は重みの位置を逆符号化する。その際にSRAM内の疎行列の値を使い、またコードブックより重みの実際の値を引っ張ってくる。その後やっと積和の演算をする。
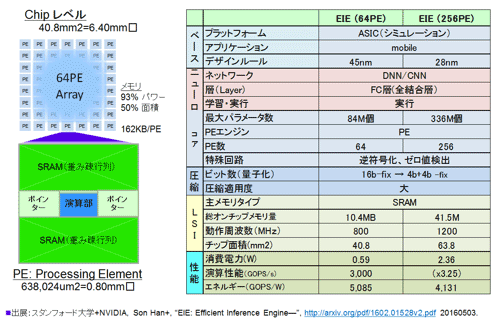
図 42 EIEの概要仕様 (参考資料46を参考に作成)
チップの構成とラフなレイアウトを、参考資料46を参考にして作成した。各PEは演算部を中心に全体の75%を占めるSRAM(重み疎行列用)が取り囲む構成となる(memoryの占有率は93%にも上る)。SRAM(重み疎行列)がパワーに占める割合は54%だ。演算自体のエネルギー消費は10%と小さい。
AlexNet8, GoogLeNet22,そしてResNet34が搭載可能
図42の右側の仕様性能を示した。オンチップメモリの量は10MB強だ。AlexNetの重みに必要なメモリ量は、非圧縮で240MB(32ビット換算)、Pruningとクラスタ化(量子化)で27分の1に圧縮されるとすると、9MB程度の重み用の容量が必要なので、ほぼぎりぎりAlexNetのネットワークが格納できる。また、畳込み層が主体のGoogLeNet22、ResNet34も圧縮率を10倍程度と見積もっても、余裕を持って搭載可能だ。
800MHz動作で、実行3TOPSの演算能力を誇る。エネルギー効率は5TOPS/Wと突出して良い。28nmを前提として4倍にすると性能は×0.8となるも、ほぼ8mm角でかなり全結合タイプのネットワーク(RNN)が実現できそうだ。
(4)圧縮方式のまとめ・・・疎圧縮、量子化、ロスレス圧縮
表7に今まで述べてきたいくつかのニューロチップの圧縮技術をまとめた。次節で説明するTrueNorthも参考に入れてある。圧縮には、重みとデータに対するものがあるが、重みにはピンク色を、データには黄緑色をつけて見やすくしている。各製品名の下に主に適用している層(Layer)を記載してある。例えばEIEは主にFC層(全結合層)に着目している。それに対してEyrissはCONV層(畳込み層)に特化している(参考資料92には全結合層での検討も行っている)。
チップで見ると、TPU、EIE、IoEが積極的で、Eyerissはオーソドックスだ。計算主体型でデータの圧縮(ゼロスキップ含め)を第一優先としていると見ることができる。
表7のように圧縮を3つに分離することができる。疎圧縮は、単純にゼロと見なしてカットしてしまう圧縮法としてまとめている。エラー率に影響が出る場合がある。量子化は、それぞれの手法により値を置き換えることによりビット数を圧縮している。ロスレス圧縮は本来損失のない圧縮方式だ。(なお、スキップ法もロスレスの手法だ)
(ア)疎圧縮
ニューラルネットワークに特に特徴的とみることができるゼロ、もしくはゼロ近辺のデータを削除(Pruning)したりスキップしたりする強引な方法だ。活性化関数ReLUが効果を倍増している。積和演算が基本なので宿命でもある(積により極小化し、和によって相殺されゼロ化される)。重みの場合には静的な圧縮で、データの場合には動的な圧縮となる。かつ両方法ともに専門的な回路を入れる必要がある。特に重りの場合には残った接続を覚えてかつ、実行では正しく動作させないといけないので複雑な印象を受ける。データの場合にはダイナミックな手法が必要(Eyrissでは、PE内部での処理に留まっている)。全結合の場合には接続が広範でかつ1対1であることからゼロと見なせる可能性が高く効果が大きい(10倍以上:元々冗長?!)。そのことから必須技術だ。
(イ)量子化
TPUは単純な線形の圧縮(Max-Min値を線形に256分類)により8ビット化を行っている。一方、Stanford大の評価(EIE:参考資料46)では8ビットでは性能劣化が大きい(AlexNet80%→53%)との報告もある。TPUでは適用例により使い分けているということかもしれない(なお、TPU自体がビット数可変である可能性もある)。
その点、EIEはクラスタ化により圧縮率を上げている。単純にやると8bitは無理だが、クラスタ化を行うと平均5.4ビット(畳込み層8ビット、全結合層5ビット)まで圧縮が可能だと主張している。特殊回路が必要だ。より質の高い方法に、前節でも述べたがIoEのフィルタ/カーネル(重み)のパターン化により圧縮法がある。高次のカーネルレベルでの符号化(特徴抽出)と見ることもできる。しかし、考えようによってはネットワークの層が進むこと自体が、カーネルの抽象化(マクロ化)であるから何が何だかわからなくなる。今後どのように進むのか興味のある技術だ。
(ウ)ロスレス圧縮
内部でかなり圧縮が進めば、効果は低く出ると考えられるが、1.5倍程度の効果が見込めるようだ。
表7 圧縮技術の一覧
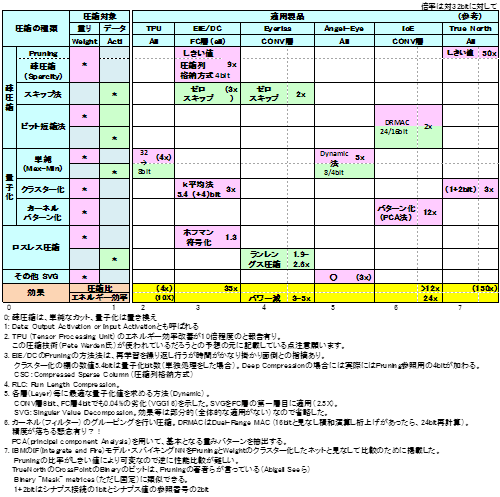
圧縮技術に関するまとめ
畳込み層(特にC型のCNN)では余り思い切った策は取りにくい。効果が比較的低めに出るからだ。(次節で述べるSqueeze Netは入れ込んでいるが)。
全結合層を主体とするネットモデルでは、積極的な展開があると想定している。場合によってはバイナリ・コネクトなりバイナライズド・ネットワークの出番かもしれない(参考資料41、42)。
初稿の段階から時間が経ち、現時点(3月)では2月のISSCC2017、及び2月後半のFPGA2017(International Symposium on FPGA 2017)の内容も判明している。簡単に述べると、畳込み層をターゲットにISSCC2017ではデータ/負荷共に量子化を行う技術の報告があった。層毎でビット数を最適化する手法(4-9bit)、さらには真にダイナミック(Real Time)に最適ビット数を検知し実行する方法の報告があった。かなり限界まで詰め切った印象を受けた。FPGA2017では1bit(Binary/XNOR) /2bit(ternary)に関する技術の報告が盛んになされた。この技術に関してはある程度技術的に方向性が見えつつ有りまた課題も見えてきた状況である。
以上、第4章では4.1節から4.3節に掛けて、CNN、DNN、および圧縮技術に関してのニューロチップの詳細を報告した。最終の第5章では最近の動向を加える。ニューロモルフィックチップとして最近新しい広がりを見せるIBMのTrueNorthと圧縮技術(Deep Compression)の実装例を紹介する。最後に本寄稿のまとめとして動向と今後の課題を述べる。
編集注)百瀬氏の現在の肩書は、北海道大学 大学院情報科学研究科 学術研究員である。
参考資料 (1〜88まではこれまでの「ニューロチップ概論」参照)
- TeraDeep社の新装のホームページ
- Market Video, "TeraDeep's Industry-First FPGA-based AI Inference Fabric Speeds Image Recognition, Video Analytics for On-Premise Appliances", October 18, 2016, TeraDeepの実質的なPress Release/Xilinx/Micron, 20181018.
- XLINX, "TeraDeep's real-time video analytics run on (gasp) FPGA-based Micron/Pico Computing AC-510 platform", XILINXのDaily Blog, 20161018.
- Yu-Hsin Chen, Joel Emer and Vivienne Sze, "Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks", 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), EyerissのFull Paper版, 2016年6月18日.
- 電子情報 2016年10月16日,"Google、IBM、AMD、NVIDIAなどがより高速な汎用インターコネクト「Open CAPI」発表。サーバを10倍高速化にすると"
- Norm Jouppi, Distinguished Hardware Engineer, Google, "Google supercharges machine learning tasks with TPU custom chip", Google Could Platform Blog, 20160518, Google, TPUの発表
- 電子情報, Stacey Higginbotham, "Google Takes Unconventional Route with Homegrown Machine Learning Chips", The Next Platform, May 19, 2016, TPUに関して比較的精度の高かった電子情報, 20160519.
- Pete Warden's Blog, "How to quantize neural networks with TensorFlow", TPUに使われていると想定されている量子化技術, 20160503.
- IT Media, "Google、人工知能応用のシティガイド企業「JetPac」を買収"
- EETimes Europe, Peter Clarke, "IoT processor beats Cortex-M, claims startup", TPUがIPコア(画像認識)としてIoTチップに搭載予定(GAP8), 20161104.
- Quoc V. Le & Mike Schuster, "A Neural Network for Machine Translation, at Production Scale", Google Research Blog, 20160927, GNMT(Google Neural Machine Translation)に関しての紹介記事(論文の発表にあたって)
- Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Lukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean, "Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation", GNMTの論文, 2016年10月8日.
- Song Han, Jeff Pool, John Tran, William J. Dally, "Learning both Weights and Connections for Efficient Neural Networks", Pruning技術、スタンフォード大学、2015年10月30日.
- Stephen Jose Hanson and Lorien Y Pratt, "Comparing biases for minimal network construction with back-propagation", In Advances in neural information processing systems, pages 177-185, 1989, 初期のPruning技術.
- Yann Le Cun, John S. Denker, and Sara A. Solla, "Optimal brain damage", In Advances in Neural Information Processing Systems, pages 598-605. Morgan Kaufmann, 1990, 初期のPruning技術(接続数を減らした).
- Babak Hassibi, David G Stork, et al, "Second order derivatives for network pruning: Optimal brain surgeon", Advances in neural information processing systems, pages 164-164, 1993, 初期のPruning技術.

