ニューロチップ概説 〜いよいよ半導体の出番(4-1)
第4章では、ニューロチップの代表的なものを9つ紹介している。第4章の1ではCNN、第4章の2ではDNN、そして第4章の3では圧縮を用いたチップについて、それぞれの特徴や機能について元東芝の百瀬啓氏が解説している。(セミコンポータル編集室)
著者:元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
第4章: ニューロチップ〜本戦に突入: 代表的なチップ
本章では、CNN(畳込みニューラルネットワーク)用、DNN(ディープニューラルネットワーク)用、さらに昨今の圧縮技術を使用している、合計9チップの詳細を扱う。技術的には、並列処理、リユース、コンフィギュラビリティ、学習機能(簡単に)、および各種の圧縮技術も含め説明する。
4.1 代表的チップ(CNN用チップ)〜並列処理、リユース、コンフィギュラビリティ
4.2 代表的チップ(DNN用チップ)〜DRAM混載もしくは学習機能
4.3 代表的チップ(圧縮技術を用いたチップ)〜疎圧縮、量子化そしてロスレス
4.1 代表的チップ(CNN用チップ)〜並列処理、リユース、コンフィギュラビリティ
本節では、CNN用のチップ(CADのみ、またはFPGA実装含み)を5チップ(nn-X/TeraDeep社、ShiDianNao/CAS、Eyeriss/MIT、IoE/KAIST、AngelEye/清華大学)を紹介する。層構成は順番にC0、CF、C0、C0、CF型であるが、畳込み層に着目し説明する。畳込み層は、重みへのメモリアクセスよりも、どちらかというとデータのアクセスおよびその計算に主体がある。そのことからアーキテクチャのポイントは、いかに3段階以上(他にタイル処理、各種層の処理等)に連なる並列処理をうまく組み上げられるか、重みの共有化(Weight Sharing)をどのように実装するか、そしてネットワークの多様性にいかに再構成(コンフィギュラビリティ)対応できるかの3つである。
(1)nn-X(TeraDeep社)・・・基本構成(3D Adderが特徴)
これは、2012年末にAlexNetが公開されて1年後の2013年後半の発表である。本格的な深層 CNN(CF型)を実装する技術が出始めた頃の発表である。FPGA上でCNNによる複数の画像認識タスクを実証(参考資料83)した。図24(a)に示すように基本演算コア(Collectionと称する)が並列(Torus状)に配置されている、ベーシックな構成だ。Collection内で連続してフィルタ処理(2D Convolution:詳細説明なし)、マックスプーリング処理(Max Pooling)、そして活性化関数処理(Programmable f(x))を行う。
入力の特徴マップ数分のCollectionを用意して、まずそれぞれで重み(先に格納する)とイメージデータを入力し2次元(2D)の積和演算を行う。そしてその中間値を、内部ルータ(Internal router)を介して横のCollectionに転送し、中間値同士の加算処理を行う(3D Conv Adderと称している)。すなわち入力特徴マップ間の和を取る。その後、プーリング処理と活性化関数処理を行い出力する。Collection数は8個であるが、マップ数が多くなると、中間値を外部メモリに格納する必要が発生し、処理の停滞が発生し速度は著しく劣化する。
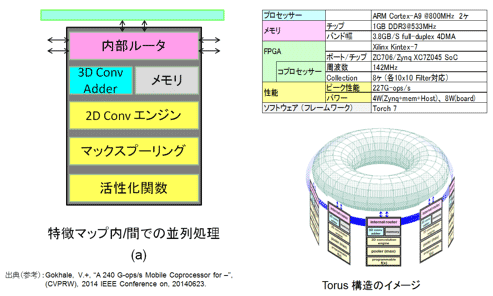
図24 nn-X(TeraDeep社)の概要仕様(参考資料83を参考に作成)
出典元:STARCの調査報告書より転載
TeraDeep社(参考資料89)は2013年Purdue大学のEugenio Culurciello准教授がYann LeCun氏を技術顧問に招き創業したベンチャー企業だ。当初よりXilinxとの結びつきが強く2015年末には投資を受けた。その後、2016年4月に本格的に拠点をシリコンバレーに移した(Campbell/Santa Clara)。同時にCulurciello准教授および大学のメンバーは手を引いた様に見える。またMicronとも近く(参考資料90、91)、3社で最近2016年10月に1000種類のクラス対応のリアルタイム物体検知技術(TD-Accel)を発表した。MicronのAC510ボード(Micron HMC+ Xilinx-Kintex XCKU060)上にTD-Accel技術(RTL)を実装し、低消費(1/2)、リアルタイム性(4x)を実現した。ビジネスターゲットは顧客施設(オンプレミス)の安心安全とのことである。
(2)ShiDianNao(CAS:中国科学院)・・・アレイ導入、重みのリユースに特徴
CASが2014年より継続的に発表しているDianNao(電脳:コンピュータ)シリーズの4番目のチップだ。カメラ・携帯電話等のモバイル用ISP(Image Signal Processor)への組込みをターゲットとしたCNN専用の高性能・画像認識用IPである。積和演算子を機能化したブロックをPE(Processing Element)と称し、2次元のアレイ状に配置している。当時(2015年)としては斬新で演算に伴うデータ移動を大幅(60〜90%)に削減できることを実証した。報告はCAD実装止まりであった。
図25(a)のシステム構成図に示すようにイメージセンサから外部DRAMを経由することなく直接画像を取り込む。CNNのネットモデルの構成は畳込み層、全結合層ともに含むCF型である(詳細は参考資料81)。認識領域は、1×32×32ピクセルとMNISTクラスで、重み(パラメータ)および中間値をオンチップの288kB SRAMで対応している。
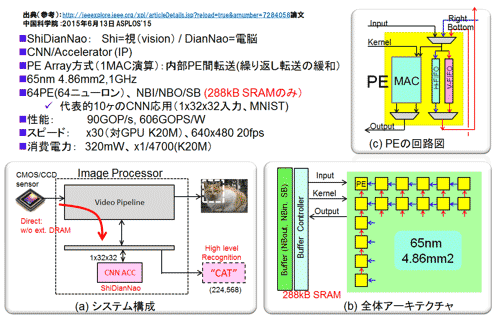
図25 ShiDianNaoの内容 (参考資料81を参考に作成)
図25(b)にShiDianNaoの全体アーキテクチャの概略図を示した。構成はバッファ部(入力:Neuron Buffer、出力、重み:Synapse Buffer)およびバッファコントローラ、そしてPE (Processing Element)を単位としたアレイ状の演算部からなる。PEは、MAC演算(1回の積和)処理を担う。8×8=64のアレイ構成だ。さらに特徴となるのは、重みのリユースを効率的に行っている点にある。入出力およびカーネルの転送パスを持つと同時に、図25(b)に赤と青の矢印で示した、PE間で入力データをリユースするための転送パスを持っている点である。逆に重みは動かない。重みのリユースのためにデータを動かしている。
(c)にPEの回路の概略図を示した。入力データ(Input)は積和の演算に使われると同時に、V-FIFO(垂直方向転送用FIFO:具体的には上側のPEに転送:実際にはH-FIFO「水平転送用:左隣のPEに転送」にも格納)に格納される。そして、次のサイクルで隣(上側)のPEに転送される。このことから、入力データを格納しているバッファ((b)図参照)へのアクセスが60〜90%削減され(PEアレイの規模に依存するが)性能が格段に改善された。特に消費電力低減の効果は大きく消費電力は320mWと1Wを切った(詳細は参考資料81を参照)。
(3)Eyeriss(MITおよびNvidia社)・・C0型、ロスレス圧縮、データスキップ、RSデータフロー
2016年2月のISSCCで発表のあったC型(C0型)のチップである(なお、発表後の参考資料92ではCF型を扱っている)。発表論文の冒頭で述べられているように、NIN(Network in Network)およびGoogLeNet(ResNetは当時未発表)の畳込み層重視の流れを汲み、全結合層はない。またロスレスのデータ圧縮技術を使用しメモリアクセス量を軽減している。DRAMは外付けだ。さらにPEコア内部で演算のスキップ(データゼロスキップ)を行っている。全体的に確実でオーソドックスな手法(エラー率に全く影響を与えない)を用いている。
(ア)回路的な特徴・・・4つの技術
図26にEyerissの回路的な特徴を論文(参考資料48)より抽出し図式化した。全体構成はフィルタとイメージの内積(一列同士のみ)を実行するProcessing Element(PE)コアを並べたPE アレイ部、SRAM バッファ、そして外部DRAMへのイメージデータ転送・転入時の圧縮/伸張部の3つからなる。

図26 Eyerissの重要な4個の技術 (論文を参考に概略図を作成:参考資料48)
第一の特長(Row Stationary):PEコアをアレイ状に並べ、データ・重み・中間値の3つのデータのPEコア間の流れ(斜め、横、上)に独自の方向性を持たせることにより、図27に示すように2nd Step以降のデータのリユースを可能とした。またその移動距離は最小(PE間)だ。基本的な考え方(特にアレイ状に並べ、重みを中心にデータを主に移動させる点)は、前述したShiDianNaoの考え方と方向性は同じだ。違いは以下の様に発展させている点である。
上述したように、フィルタとイメージの内積を一行(Row)同士で行っている。ISSCC2016での発表の後で公開となった論文ではその点をEyerissの特徴として強調している(参考資料92:なお、全結合型まで言及)。彼らは列固定データフロー(Row Stationary (RS) dataflow)方式と命名している(Stationaryは、フィルタ値の流れを行方向に限定して再利用可能としているという意味合いらしい)。また1DConvolutionと呼んでいる。ベクトルとベクトルの内積処理を1つのPEコアで行う。ShiDianNaoはPEコア内で基本演算、すなわち数値と数値の積和しか行っていない。これを0次とすると、ShiDianNaoは0次のPEコア、Eyerissは1次畳込み処理のPEコア、nn-x(TeraDeep)は2次のコア(同列に並べるのは無理があるが)となる。余談だが、この流れから3次の処理は入力特徴マップ間の加算処理(3D Adder)、4次は出力特徴マップ間の並列処理となる(独立処理なのでコアを並列に並べるだけでよい)。なお、この次元数は畳込み層のフィルタが4次元である点と呼応している。
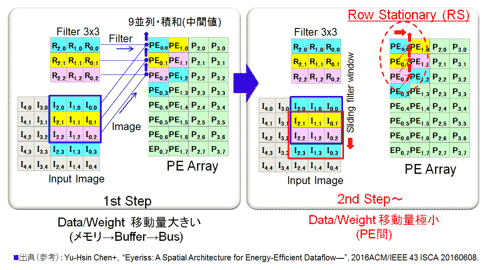
図27 列固定データフロー (Row Stationary Dataflow)方式
(論文を参考に概略図を作成:参考資料48, 92)
第二の特長 (演算スキップ):PEへの入力データがゼロの時に演算をスキップ(消費電力を45%削減)させる技術だ。前段の活性化関数にReLU (Rectified linear unit)を使っていれば50%程度の削減は予想の範囲だ。この技術はPEアレイ部が消費する電力が図28の表に示すように78%と大きいことからチップ全体として効果は絶大だ。なお、後述(4.3節)するDeep Compression技術の入力値(ベクトル内の値)のゼロスキップと同じである。必須技術だ。
第三の特長(ランレングス圧縮):出力データのランレングス圧縮(ロスレス:データ圧縮量約1/2)を導入した。中間データ、層出力データを外付けメモリに格納する必要がある場合の技術である。層の出力が次の層の入力となることから、外に格納する必要がない場合には意味がない。
第四の特長(NoC/Multicasting):各PEコアにIDを付加しNoC (Network On Chip)によってデータ転送を制御することで、基本機能はもとより再構成性および低消費電力化を実現している。3つの基本機能は(参考資料92)、データのマルチキャスト、フィルタのマルチキャスト、そして中間値(P-sum)のPE間の転送制御だ。
第五の特長(リコンフィギュラビリティ):5番目の技術は彼らが最も重要と考えている再構成可能技術(Reconfigurability)だ。アプリケーション(ネットワークモデル)もしくはネットワークの各層によって変わる入力特徴マップ数、出力マップ数、フィルタの数、さらにはフィルタサイズと(最近は1x1もしくは3x3に集約しているが)とフィルタのストライドの変化に対応可能だ。具体的でまとまった記述はないが、AlexNetの各層(構成がバラエティ)に適用してPEアレイのPE使用率が平均88%であることからレベルは高いと見た。いくつか論文より手法のポイントを拾い上げると、(1)Array構成となっていることから柔軟な対応が可能で、(2)中間値を自由に扱えるようにし、(3)IDにより特定のPEに選択的にアクセス可能とし、さらに(4)Multicastが柔軟にできることから効率が上がる等の細かい技術(半ばノウハウ)が再構成可能(Reconfigurability)性を支えていると推測した。
考察
図28に特性一覧をまとめた。AlexNetの5つの畳込み層の処理で、スループット34.7fpsを記録した。どの程度のものなのか簡単に試算検証してみた。AlexNetの必要演算数は、10.8億回(1.08 Billion回:畳込み層のみ)のMAC処理(第1章、表1)である。Eyerissの性能を84GOPS(図28内の表)とすると、処理時間は、1.08x2/84=0.026秒。すなわち39fps。実測値とほぼ等しい(通常7〜8割)。GoogLeNet22の必要処理回数は、15億回、ResNet34は、36.4億回であることから、エラー率5%程度(ILSVRC/Imagenet)で10〜30fpsの画像認識ができることがわかる。しかも65nmプロセスと数世代前の技術で0.3W程度が達成されたとみなせる。
なお、Eyerissではデータの圧縮(可逆圧縮)は行っているが、4.3節で詳細説明するデータ及び重みの圧縮技術(言わば非可逆圧縮)、例えばPruning(枝そぎもしくは剪定:後述)技術を使用していない(このPruning技術のスタンフォード大学の発表は2015年中盤である)。理由は以下と推測する。まず特有の回路を入れるペナルティ(ソフトで対応する手もあるが効果は小さいと言われている)、および全結合層ほどの効果がない点である(もちろん無視できない効果だが)。仮に入れれば100mWを切ったかと推定する。なお、Eyerissでは16ビット固定小数点を用いている。
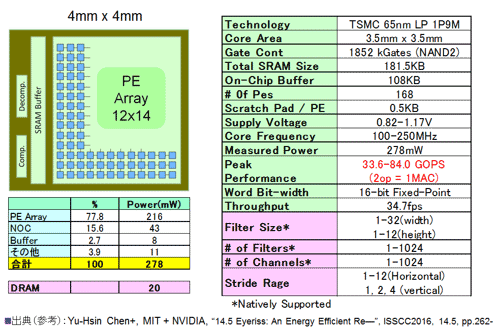
図28 Eyerissの概要仕様 (参考資料48を参考にまとめた)
(4)IoE(KAIST)・・・カーネル圧縮、低消費電力(45mA)
2016年ISSCCで発表されたチップである。256個のMAC演算子を有して、125MHz動作であることから256MAC×125MHz×2(1MAC=2Ope) = 64GPOSとなり、チップの消費電力が45mWである。また1.42TOPS/Wのエネルギー効率を達成した。Eyerissとチップサイズ、ゲートサイズ、周波数等が似ている。パワーがEyerissの278mWに対してIoEが45mWと1/5程度である。入力の条件等不明な点もあり比較が難しいが、大きく違っているのはIoE独自のカーネル(フィルタ)の圧縮法を採用していること。フィルタの量が8%、1/12に軽減され、負荷転送量がそれ相当に軽減される。この技術によりかなりその差が出ると推測する。ただし全ては説明できない。処理能力は64GOPSでこれもEyerissと同等である。64GOPSの処理速度だと3×224×224ピクセルの画像認識処理を数十fpsの速度で行える。図29にIoEの4つの技術的な特徴をまとめた。2番目と4番目の特徴に関し、以下に説明を加えた。
2番目の特長:Dual-range MAC (DRMAC) 回路(詳細回路構成は参考資料71)
24ビットを基本のビット数としている。24ビット(16、8)固定小数点の出現比率が0.01%と小さく、また99%が16ビット(8、8)で十分であることから下位16ビットのみを使用し、上位8ビットはマスキングし積和(MAC)処理をしている。MAC演算によりキャリーオーバーが発生した際には戻って24ビットで再計算を行う。入力データ、重みの両方に適用している。この技術でパワーはブロック当たり44%削減される。効果は大きい。詳細が不明な点はあるが、1%の量の大きな値を小さな値に丸め込んでいることにより精度が落ちるという関連報告(参考資料45)があった。すなわち頻度に合わせて量子化(クラスタリング)を行うと、Max値が無視され精度に影響が出ることと類似していると推測する。
4番目の特長:カーネルデータの圧縮(DRMAC回路を併用):
図29(b)に示した様に、事前にPCA(主成分分析)によりオリジナル(実際の)カーネルを基本的なカーネル(k1, k2・・・)に重みを付けて分解し軽量化し(カーネル自体のクラスタリング)、実行演算時には少ないデータを外部メモリより転送してオリジナルカーネルの生成を行う。その生成も図29(b)に示すようにMAC処理なのでDRMAC回路を併用できる。圧縮効果は12xで精度のロスは0.68%だ。気になる点もある。昨今カーネルサイズが小型化し3x3が主流なのでネットモデルによっては効果が小さい場合もあると推測する。とはいえカーネルの単位である重み(ビット数)での圧縮(量子化:4.3節にて説明)よりカーネル全体での分類(圧縮)であることからより高次の圧縮技術とも見なせる。Eyerissがオーソドックで完成度が高いのに対して、IoEはDRMAC回路の併用も加えて全体にスマートな印象をうける。
圧縮率が12xでロスが0.68%(他の技術より大きいが)で消費電力が45mWという点は、際だってよい印象を受ける。ただし精度よく判断するためには情報が足りない。ネットワークの詳細規模が不明だ。また前述した45mWに関してどこで電力を消費しているのかも知りたい点だ。IoEと称していることからミッドクラス(サイズと精度)と想像する。カーネルデータの圧縮を一層極めて欲しい。
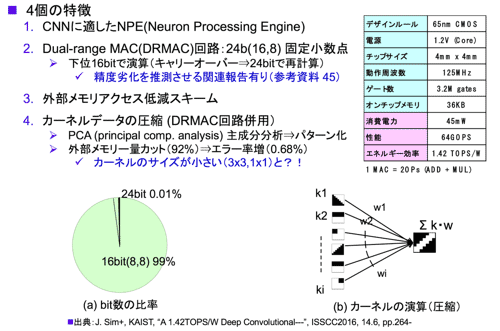
図29 IoE (KAIST)の技術の特徴とチップの概要仕様 (参考資料71を参考にまとめた)
(5)AngelEye (清華大学)・・・CF型、標準型、FPGA実装
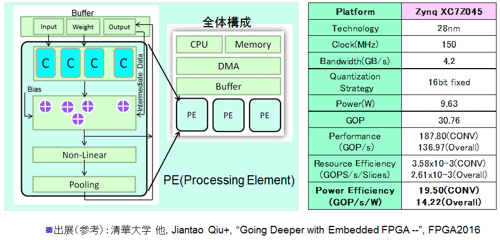
図30 AngelEyeの構成と概要資料 (参考資料56を参考にまとめた)
CNN用のチップとして最後に清華大学のAngelEyeの回路構成と仕様を図30に示した。前節3.3で説明したようにAngelEyeに関して、CF型のCNNをFPGAに搭載、そのパワーは、9.63Wと大きい。筆者らもコメントしているように後段の全結合層部分のDRAMアクセスがパワーの大きくなった要因だ。なお、結果を明示的に報告していないが8/4ビット(前者が畳込み層、後者が全結合層)への量子化をネットの層毎(ダイナミック)に行う技術を報告している。
編集注)百瀬氏の現在の肩書は、北海道大学 大学院情報科学研究科 学術研究員である。

