ニューロチップ概説 〜いよいよ半導体の出番(3-3)
第3章の3.3では、これまで開発されたチップを、CNNとDNN/全結合層に分け分類している。それぞれのチップがどのような位置づけにあるのかも理解できるようにグラフ化している。第3章のこれまでの参考資料をまとめている。(セミコンポータル編集室)
著者: 元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
3.3チップ性能一覧と技術的ポジショニング
本節では、第4章で説明する10個のチップを俯瞰できるように性能一覧表を用いて説明する。またグラフを用いて各チップの技術的なポジションを示す。
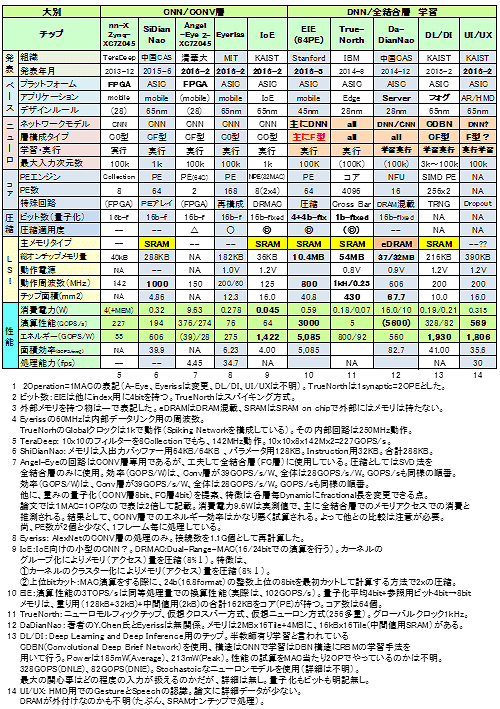
表6 代表的ニューロチップ 仕様一覧
(1) 仕様一覧の内容
表6の仕様は比較的そろいのよい項目を選択した。チップコード名のなかで、IoE、DL/DI(Deep Learning/Deep Inference:参考資料86)、およびUI/UX(参考資料87)は論文のタイトルから引用して命名した。ほとんどのチップがASICである(少し引用に偏りがあった)。まず全体をCNNとDNN(狭義のDNN)のカテゴリーに分けている。層構成(C型とかCF型)のタイプから判断して二分している。CNNのカテゴリーでは層構成C0型が3チップ、CF型が2チップである。
スタンフォード大学のEIE(Energy Efficient Inference Engine:参考資料46)は、圧縮技術(Deep Compression 参考資料45)用の特殊回路コア検証をモチーフとしたエンジンである。CF型・F型を対象としているが主に全結合層を検討の対象としている。このことからDNNのカテゴリーに入れた。
DL/DIをどちらに入れるかかなり迷ったが、DNN/全結合 学習のグループに入れた。このチップはRBMを学習の基本とするDBN (Deep Brief Network)のネットモデルに畳込み(Convolutional)の手法を取り入れている。本来なら左側のCNNに入れるべきだが、DBNを強調するために敢えて右に入れている。
表では目立つよう記載していないが、TrueNorth(参考資料84, 85)はこの表で唯一のクロスバー方式(実際は仮想クロスバー方式もしくは仮想ニューロン方式:時分割多重を用いる:5.1節で説明)であり、かつニューロモルフィックチップである。入力と出力がアレイ状(クロス状)に配置されその交点が接続と重みを表現する。
これに対して他はバス方式である。バスに演算用のコア(PE:Processing Engine/Element)を並列、もしくはアレイ状(必要に応じてNoC:Network on chipの搭載される)に配置しデータおよびパラメータ(フィルタ値、重み)をバスから供給する。動作クロックに比例して演算速度は増大する。
メモリ混載は重要なファクターだ。DaDianNaoはバス方式であるが、オンチップのDRAMにパラメータを格納することにより、パラメータアクセス時間の短縮、さらにスケーラビリティーの向上、そしてその結果として畳込み層はもとより全結合層の演算性能向上を追求する。それだけに留まらず動的再構成機能・学習機能をも搭載した野心的なチップだ(実際にはCAD実装まで)。なおKAISTのDL/DIおよびUI/UXは共に学習機能を搭載したチップである(残念ながら理解できるレベルの詳細情報は公表されていない)。
その他、表として重要なポイントを上げると、最大入力次元数に回路の規模が比例する。ShiDianNaoの入力次元数は1kであり、MNISTの32x32の入力を扱う小規模なものだ。仕様、例えば消費電力を比較する際には最大の入力次元数にも注意が必要である。残念ながら入力の次元数の記載のないものもある。
圧縮技術の搭載状況をビット数と適用度のレベルで示した。例えば◎はかなり大がかりに圧縮技術を適用しているものを示す。EIEとIoEが両雄である。圧縮の詳細内容に関しては後述する(4.3節)。なおEIE/IoEの実効ビット数は記載値より幾分大きい。またTrueNorthは1bit(バイナリ:最近はターナリ)と称されているが、実効的には若干多い。
LSIとしての幾つかの性能を下段にまとめた。性能を横並びに比較するのは極めて危険な場合がある。仕様により大きく変わる。まずメモリ混載の有無、学習機能の有無、次にネットの構成型(C0/C1、及びCF/F型)、そして規模(入力次元数)により大きく異なるので留意が必要だ。
(2)各チップのポジション
各チップのポジションをわかりやすくするために、層構成(CONV層/FC層:Fully Connected)と圧縮の有無で分けマッピングした(図23)。チップのコード名の横にエネルギー効率(GOPS/s/W)を添えた。その値によりマークの大きさを変えた。1TOPS/s/W以上だと大きなマークを使用した。
また、表6にはないGoogleのTPU(参考資料、88)をデータとして加えた。究極の形として、CNNのC0型のモデルであるSqueezeNet (Deep Compressionを適用:参考資料50)、またNMT(Neural Machine Translation:ニューラル機械翻訳:RNNモデルベース、参考資料72、73)にPruning技術を付加した結果も加えてある。さらにTrueNorthも配置した。圧縮の視点から見ると、スパイキングをPruning(自動で行っている)、接続をバイナリ量子化、さらに重みをクラスタ分類していると類似できると考えた(多少無理があるが)。
初期(1〜2年前)のCNN、学習機能を有するもの、最新のCNN、さらにスタンフォード大学提唱のDeep Compression(DC)を適用したものがわかるように、グルーピングした。
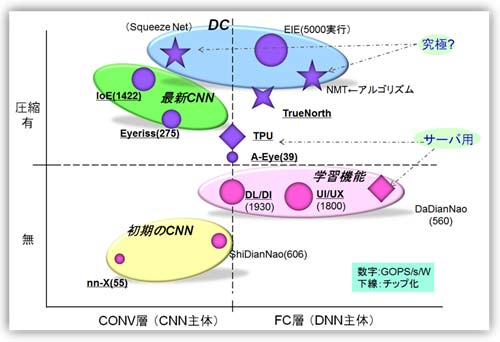
図23 各チップのポジショニング
第3章では3.1節〜3.3節にて、基本的な回路構成の基本(特に畳込み層)に関して説明を行い、また最近(2016年前半)までのニューロチップの概要を網羅的に説明した。次章(第4章)以降では、チップの詳細をCNN用(4.1節)、DNN用(4.2節)、そして圧縮技術(4.3節)を用いたチップに分けて説明する。
参考資料 (1〜55までは第1章と第2章を参照)
- Jiantao Qiu, Jie Wang, Song Yao, Kaiyuan Guo, Boxun Li, Erjin Zhou, Jincheng Yu, Tianqi Tang, Ningyi Xu, Sen Song, Yu Wang and Huazhong Yang, "Going Deeper with Embedded FPGA Platform for Convolutional Neural Network",2016ACM pp.26-, FPGA'16, 清華大学、Angel Eye, 2016222
- Jeff Gehlhaar, "Neuromorphic Processing: A New Frontier in Scaling Computer Architecture", ASPLOS'14:Architectural Support for Programming Languages and Operating Systems, http://www.cs.utah.edu/asplos14/files/Jeff_Gehlhaar_ASPLOS_Keynote.pdf, https://dl.acm.org/purchase.cfm?id=2564710&CFID=687971028&CFTOKEN=91213122、Qualcomm, Neuromorphic技術, 20140304.
- Qualcomm Snapdragon Blog, "Snapdragon 820 Automotive processors debut at CES 2016", Qualcomm, SD820A, 20160106.
- Qualcomm 仕様書, "Qualcomm Snapdragon 820A: Industry's first automotive grade SoC with integrated X12 LTE modem", Qualcomm, SD820A仕様書, 2016年.
- EETimes, Junko Yoshida, 電子情報、2016年1月27日, "Google's Deep Learning Comes to Movidius/ Moving machine vision from data centers to devices", MovidiousのGoogleとの共同開発 発表 (インテル買収後も自社ホームページは変わらず、DJIとのプロジェクト内容も記されている), 20160127.
- Product Brief, "Myriad 2 Vision Processor", Myriad2の概要仕様, 2014年7月.
- Movidius社のHP, "Embedded Neural Network Compute Framework: Fathom", FathomおよびFathom USB Stick情報, Movidius社, 2016年.
- TechCrunch Japan(日本語)電子情報, "Movidius、今度はFathomを発表-どんなデバイスもUSBスティックでニューラルネットワークが利用可能", Fathom, Movidius社, 2016年4月29日.
- Movidius社ホームページDJI, "DJI Unveils Mavic Pro Drone, Powered by Movidius", MA2155をDJI Droneに使用、2016年9月27日.
- Movidius社ホームページ, "Movidius + Intel = Vision for the Future of Autonomous Devices", VPU+Intel RealSense, 20160905.
- Mike Demler, "Mobileye Increases Car EyeQ Computer-Vision Processors Will Enable Autonomous Vehicles", Microprocessor Report Insight Analysis of Processor Technologies, Mobileye, EyeQ4, 20150720.
- Press Release Details, "The Road to Full Autonomous Driving: Mobileye and STMicroelectronics to Develop EyeQ(R)5 System-on-Chip, Targeting Sensor Fusion Central Computer for Autonomous Vehicles", Mobileye, EyeQ5, 20160517.
- Nervana社のホームページ, "NERVANA HAS JOINED INTEL", Nervana社、Intel合併、20160823(合併).
- Synopsys社ホームページ, "DesignWare EV5x Vision Processors", EV5シリーズ, Synopsys, 2015年3月.
- Synopsys社Web, "Design Ware EV6x Embedded Vision Processors", もしくはhttp://www.synopsys.com/Japan/press-releases/Pages/20160601.aspx EV6シリーズ、20160602.
- Jaehyeong Sim; Jun-Seok Park; Minhye Kim; Dongmyung Bae; Yeongjae Choi; Lee-Sup Kim, "A 1.42TOPS/W deep convolutional neural network recognition processor for intelligent IoE systems", 2016 IEEE International Solid-State Circuits Conference (ISSCC), Pages: 264 - 265, IoE, KAIST, 20160131.
- Abigail See, Minh-Thang Luong, and Christopher D. Manning, "Compression of Neural Machine Translation Models via Pruning", Stanford大, NMT (Neural Machine Translation)へのPruning適用, 20160629.
- Abigail See, "CS224N Final Project: Exploiting the Redundancy in Neural Machine Translation", Stanford大, NMT (Neural Machine Translation)へのPruning最初のアプリケーションへの適用, 2015年10月頃.
- Danny Shapiro, "Automotive Innovators Motoring to NVIDIA DRIVE", NVIDIA Official Blog, NVIDIA DRIVE PX2, 20160104(CES).
- Wikipedia Multilayer perceptron (MLP)
- Geoffrey Hinton, A Practical Guide to Training Restricted Boltzmann Machines, トロント大学の教材, RBM, 20100802.
- Ruslan Salakhutdinov, Geoffrey Hinton, "An Efficient Learning Procedure for Deep Boltzmann Machines", Neural Computation 24, 1967-2006 (2012), RBM, 2006年8月24日.
- Geoffrey E. Hinton, Simon Osindero, and Yee-Whye Teh, "A fast learning algorithm for deep belief nets", Journal Neural Computation archive, Volume 18 Issue 7, July 2006, Pages 1527 - 1554 MIT Press, DBN, 2017年7月.
- Geoffrey E. Hinton; Ruslan R. Salakhutdinov, "Reducing the Dimensionality of Data with Neural Networks". Science 313 (5786): 504-507, Auto Encoder, 20060728.
- Honglak Lee, Roger Grosse, Rajesh Ranganath, Andrew Y. Ng, "Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations", Proceeding of the 26th Annual International Conference on Machine Learning ICML 2009, Pages 609-616, CDBN, 20090614.
- Zidong Du, Robert Fasthuber, Tianshi Chen, Paoio Ienne, Ling Li, Tao Luo, Xiaobing Feng, Yunji Chen, Olivier Temam, "ShiDianNao: Shifting Vision Processing Closer to the Sensor", CAS, University of CAS, EPFL, Inria(フランス国立情報学自動制御研究所), The 42nd International Symposium on Computer Architecture (ISCA42/2015), ShiDianNao, 2015年6月13日.
- Bernard Bosi, Guy Bois, and Yvon Savaria, "Reconfigurable pipelined 2D convolvers for fast digital signal processing", IEEE Trans. on Very Large Scale Integration (VLSI) Systems, 1999 Sep ;vol. 7 (no. 3): page 299-308, 再構成可能2Dのコンボルバ-.
- Vinayak Gokhale, Jonghoon Jin, Aysegul Dundar, Berin Martini, and Eugenio Culurciello, "A 240 G-ops/s Mobile Coprocessor for Deep Neural Networks (Invited Paper)", Computer Vision and Pattern Recognition Workshops (CVPRW 2014), 23 June 2014, Teradeep/nn-X, 2014623.
- Paul A. Merolla, John Arthur, Rodrigo Alvarez-Icaza, Andrew S. Cassidy, Jun Sawada, Nabil Imam, Steven K. Esser, Myron D. Flickner, Dharmendra S. Modha, "A million spiking-neuron integrated circuit with a scalable communication network and interface", Science 8 August 2014: Vol. 345 no. 6197 pp. 668-673, 雑誌Scienceに載ったIBM, TrueNorth、20140808.
- TrueNorthの補足技術資料, 2014年8月8日, http://www.sciencemag.org/content/suppl/2014/08/06/345.6197.668.DC1/Merolla.SM.rev1.pdf.
- Seong-Wook Park, Junyoung Park, Kyeongryeol Bong, Dongjoo Shin, Jinmook Lee, Sungpill Choi, Hoi-Jun Yoo, "An Energy-Efficient and Scalable Deep Learning/Inference Processor With Tetra-Parallel MIMD Architecture for Big Data Applications", IEEE Trans Biomedical Circuits Systems, vol.9, No.6 Dec 2015, PP.838-48, KAIST, DL/DI, ISSCC2015 4.6のFull Paper版)、 2015年12月9日.
- Seongwook Park, Sungpill Choi, Jinmook Lee, Minseo Kim, Junyoung Park and Hoi-Jun Yoo, "A 126.1mW real-time natural UI/UX processor with embedded deep-learning core for low-power smart glasses Purchase", Solid-State Circuits Conference (ISSCC), 2016 IEEE International, 14.1, KAIST, UI/UX, 2016年1月31日.
- Norm Jouppi, "Google supercharges machine learning tasks with TPU custom chip", Google Cloud Platform Blog, May 18, 2016, Google, TPU, 2016年5月18日.

