
ニューロチップ概説 〜いよいよ半導体の出番(5-2)
ここでは、GoogLeNetやResNetの良い点を取り込んだ、Squeeze Netと呼ぶシンプルなモデルについて検討している。その圧縮技術に適用した結果も紹介している。(セミコンポータル編集室)
著者:元半導体理工学研究センター(STARC)/元東芝 百瀬 啓
5.2 究極の姿へ(一定のレベルへ)〜シンプルなモデルへの適用とNMTへの展開
この寄稿が皆様の目に触れる頃には、ImageNet/ISLVRC2016やNIPS2016も終了していると考える。その時にどのようにネットワークモデルが進化しているのか気になるところではある。GoogLeNetなりResNetを越える新しい考え方があるのだろうか。本節では、ネットワークモデルさらに圧縮技術もある一定レベルの形にまとまりつつある(タイトルには究極と入れたが)との認識の元に、現状の技術の広がりを概観しておく。 まず、シンプルなSqueeze Netを紹介し、そこへの圧縮技術適用結果を紹介する。最後に、NMT(ニューラル機械翻訳)への適用の状況を述べる。
(1)まとまってきたネットワークモデル(Squeeze Net)
第2章で触れたが2016年の2月にArxivに発表されたSqueeze Netに関し紹介しておく(参考資料50)。著者はUC BerkeleyのF. N. Iandola氏である。Deep Compressionの開発リーダのスタンフォード大学のS. H. Han氏も共同執筆者である。F. N. Iandola氏はAIビジネスを行うDeepScale社(参考資料112)の実業も行っている。その点から技術内容に極めて実務的な印象を受けた。オリンピック級は狙っていない。画像認識の精度のターゲットをグッと落としてAlexNet当時のレベル(80〜85%の精度)にしている。逆に効率よくわかりやすく組み上げ、操作しやすくしているのが特徴だ。
Squeeze Netと名前を付けているが、著者も述べているようにNIN(Network in Network)、GoogLeNet、さらにはResNet(参考資料26, 27, 28)の技術の良い点を単純に取り込んでいる。ただし、それらを上回ることにあまり関心はないようだ。CNNのC0型の構成だ。画像認識をターゲットとしてミッドレンジの精度で、最も高効率(サイズと精度)を目指している。
参考資料をベースに図50を作成した。左側にSqueeze Netのモデル全景を示した。黄色は畳込み層、水色はMax Pooling層(1/4)である。ピンク色の部分が核心となるFire Moduleである。合計8モジュール入っている。Fire Moduleの中身は右図に展開しているように、3つのピンク色の畳込み層から形成されている。1×1のSqueeze層と、1×1と3×3が並列に並ぶExpand層からなる。数値はチャンネル数(特徴マップ数)だ。余談だが、C0型はフィルタだけが明示的に書かれるのが昨今の流れである。マップのサイズは、Pooling層の位置をみて容易に判断できる。
Fire Moduleの各ブロックの働きを考える時に、そもそもフィルタとは何かであるが、1×1では情報を畳み込んでゆく力は本来ない。主役は3×3のフィルタだ。だが3×3のフィルタでも入力96チャンネル(入力の特徴マップ数)を直接入れると莫大な重みの数が、そして計算量が多くなる。そこで、前段にSqueeze層と称して1×1を置きチャネル数を絞り(Squeeze)、そしてExpand層の内部には並列に1×1を置き3×3をがっちりガード(実質的にチャネル数を折半)して過度のフィルタ作業(極力チャンネル数を下げる)をさせないようにしている。なお、技巧的には、Squeeze層の1×1はNIN (Network in Network)のBottleneck層と全く同じだ。
そしてじわじわと1000チャンネル(チャンネル数が仕分けるクラス数)までの階段を上る。層数と不良率は、Squeeze Netは18層で15.3%の不良率、GoogLeNetは22層6.7%、ResNetは34層3.57%となる。急いで1000段の階段を上ると能力以上にジャンプすることから不良率も上がる。ゆっくり登れば、取りこぼしも少ない。いかにゆっくり登れるかが精度アップのポイントだ。
Squeeze Net(他のNetも基本はかなり同じだ)の原理は以上である。ただし、Squeeze層の絞りこみがきついと情報が次段に伝わらない。その対策として登場したのが図50には記載していないがショートカットループだ。情報を先にリークし伝達する。バイパスをもつResNetのショートカットループのことだ。なおこのSqueezeネットに限らず全般的に理論的な説明はあまりない。
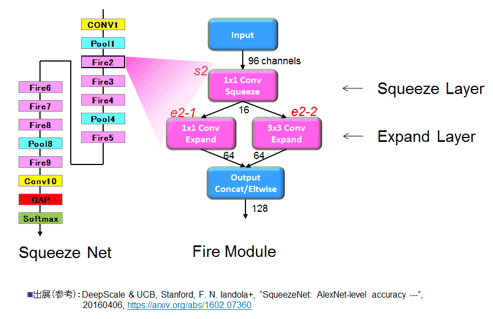
図50 Squeeze Net全景と、Fire Moduleの内部構成 (参考資料50を参考に作成)
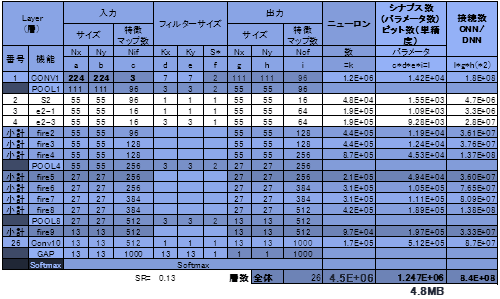
表8にネットを構成する入力サイズ、マップ数、フィルタサイズ、出力サイズ、マップ数を、またニューロン数、接続数を各層ごとに計算し一覧とした表を参考として示した(筆者が計算をトレースした)。サイズ的には、18層、1.3M個重み、8.4億回MAC演算、15.3%エラー率だ。構造として近いGoogLeNet22の値を示すと、22層、7M個重み、15億回MAC、6.66%となる。Squeeze Netはパラメータ数が1/5で、やはりミッドレンジクラスだ。
表8でFire2モジュールのみ内部を明示してあり、Squeeze Layer S2、Expand Layer e2-1とe2-2の値が見えるようにしてある。他のモジュールはモジュールの和として値を示した。なお、論文では各パラメータの感度(sensitivity)も評価しており、丁寧でかつかなり直感的に読めるので一読をお勧めする。
表8 Squeeze NetにAlexNetモデルを適用した際の各層のパラメータ一覧
(2)圧縮技術を適用する〜畳込み層だけだが〜
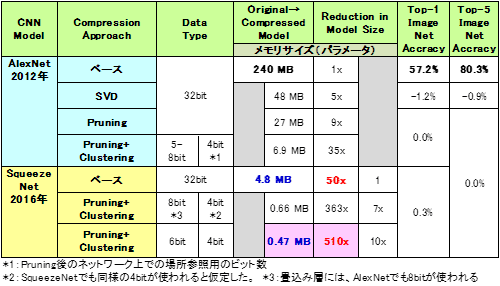
表9に、Iandola氏らがSqueeze NetにPruningとクラスタリング(量子化)を適用した際のパラメータ数の変化と、ベンチマークのImagenet/ILSVRCのTop1とTop5の精度の値を転載し、情報を加えて比較表にした。最上段の値57.2%と80.3%がベースの値だ(ベストの値ではない)。AlexNetに圧縮技術を適用した場合と、Squeeze Netに適用した場合の圧縮率と、精度の変化を示した。精度の変化(劣化)はMaxで0.3%と極めて小さい。一方、圧縮率はAlexNetで35倍(これは4.3節で紹介した値と同じ)に対してSqueeze Netでは10倍しか圧縮されていない。AlexNetは全結合層を持ち、その圧縮率が大きいからである。まとめると、ネットワークモデルの効率化で50倍、圧縮技術で10倍の効果があり、対AlexNet比500倍の改善がなされたことになるというのが彼らの結果である。メモリ容量では、0.47MBと極めて小さく、容易にSRAMオンチップ化が可能だ。
表9 SqueezeNetとAlexNetとの比較と圧縮技術適用の結果
参考資料50を参考に作成
(3)圧縮技術の自動翻訳(NMT:Neural Machine Translation)への適用
図51にStanford大学のAbigail See氏らが発表しているNMT(参考資料72, 73)モデルのアーキテクチャを示した(資料を参考に作成)。モバイルへの搭載をターゲットとし、Pruning技術の適用を検討した。実装の検討はしていない。英語からフランス語への機械翻訳である。彼女らの例では5万個という英語の単語(ボキャブラリー数:ワンホットベクトル)を時系列的に分散表現(word embeddings:単語間の関連性1000次元(n)のベクトルで表現)する。同時に対となるフランス語にも同様の表現を施し、両言語の因果関係をつけ学習(教師有り)する。ソース側(エンコーダ側:英語)とターゲット側(デコーダ側:フランス語)を横に積み重ねた2重のRNN (2Stacked RNN) 構成である。
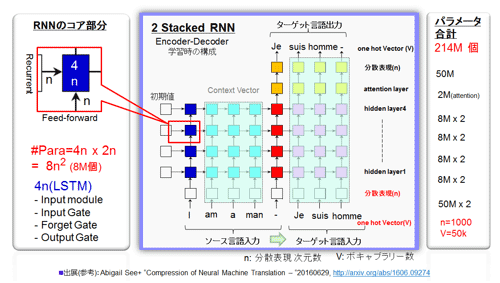
図51 2 Stacked RNN (LSTM) 構成からなるNMTモデル (参考資料72、73を参考に作成)
(ア) モデルの構成
学習の際には、入力側より文章(Sentence:I am a manと、Je suis homme)を入力し、ターゲット言語出力(上側)での誤差(Je suis hommeとの差)を誤差逆伝播法でフィードバックする。全て全結合である。
縦方向の層構成(Feedforward側)は、最初に単語(ボキャブラリー)を分散表現に変換する処理層がある。V=50kとn=1000の全結合層により変換される。5万次元から1000次元へと圧縮された後に、時系列的のRNNに入る。彼女の構成は縦方向4層の隠れ層(hidden layer)をもつ。1000次元で上層に繋がる。隠れ層の上側には、Attention層(説明省略)と分散表現から単語に戻す層(50k×1k)がある。最上層には重みのないSoftmax層があり、全単語(ボキャブラリ)の確率を出力する。
横方向の層構成(Recurrent側)は、ソース側の第一列(英語のI)があり、その後に次の時刻に来る第二列(英語のam)が来る。"am"は"I"との関連(例えば文法)があるので、横方向のRecurrentのパスを受ける。さらに右側に来て、デコーダー側にぶつかりフランス語側での時系列の処理を行う。実際には、図のソース言語側の左側(紺色の列)の列とターゲット言語側の左側の列(赤色の列)が実在し、時系列的に仮想アレイを構成し図の様な形になる。
コア部分はLSTM (Long Short-Term Memory) からなる。次元は上下左右共にn(=1000)だ。よって4nの次元となる。入力は縦側のFeedforward側が同じくn(=1000)、横方向のRecurrent側がn(=1000)となり、コアでのパラメータ数は4n×2n =8n×n (n=1000) となることから、コア当たり8M個持つことになる。
(イ) パラメータ数
図51の右側に各層のパラメータを記載した。時系列展開の仮想分は含まない。下側の分散表現および隠れ層(全部で4層)の部分はソースとターゲットで2倍となる。合計は216M個(論文では214M個だが計算ミスかもしれない)となる。分散表現への符号化と逆符号化の合計150M個が全体の75%を占める。すなわち全結合の宿命であるがボキャブラリの数に強く依存する。図52にNMT (自動翻訳) のポイントを追加した。なお、このNMTに限り入力次元数は入力と初段の層のルート平均(10の4乗)とした。
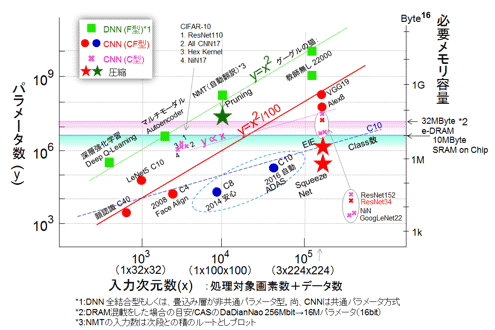
図52 ネットワークモデルとパラメータ数(メモリ容量)との関係(圧縮モデルを追加)
(ア) 圧縮(Pruning)技術の適用
Deep CompressionのHan氏らと同様に、Training - Pruning - Retrainingの手順を採用している。またPruningは全パラメータを小さい順に並べ、しきい値でカットしている。その結果、性能を落とさずにパラメータを20%まで圧縮することが可能だった。214M個が42M個に圧縮された(参考資料72ではストーレジ量での記載があるが、本寄稿ではパラメータ数を使用した)。図52にNMTの圧縮後の値を緑の星★でプロットした。AlexNetの62M個に対しては少ないが、依然かなりの量である。同様に、EIEとSqueeze Netの圧縮後の値も赤い★で追加した。
機械翻訳の精度の劣化もなく、重み数42M個とメモリをオンチップ可能なレベルまでもう一歩という印象である。画像認識に続き、実は言語を扱うことから難易度が高い機械翻訳(GNMT: Google Neural Machine Translationの報告(参考資料99, 100)含め)や、同種の音声認識をテーマとしたLSI実装の検討が今後一層重要となる。
編集注)百瀬氏の現在の肩書は、北海道大学 大学院情報科学研究科 学術研究員である。

 インサイダーズ
インサイダーズ インサイダーズ
インサイダーズ インサイダーズ
インサイダーズ インサイダーズ
インサイダーズ インサイダーズ
インサイダーズ セミコンポータル編集長
セミコンポータル編集長 半導体関連市場の動向
半導体関連市場の動向 技術コンテンツ
技術コンテンツ 経営・戦略ビジョン
経営・戦略ビジョン トピックス解析コラム
トピックス解析コラム