
ニューロチップ概説 〜いよいよ半導体の出番(3-1)
第3章以降は、ニューラルアーキテクチャを半導体チップ上で実現した、ニューロチップについて、元STARC/東芝に在籍し、現在北海道大学に勤務する百瀬啓氏が解説する。これからのAI(人工知能)を差別化する手段の一つが半導体チップであることから、今後きわめて重要な解説論文となる可能性がある。ただ、この寄稿は長いため分割・掲載する。(セミコンポータル編集室)
著者: 元半導体理工学研究センター(STARC)/元東芝 百瀬 啓 (編集注)
当初は第3章でチップの回路技術、アーキテクチャを解説する予定だったが、チップの動向が大きく変化してきたため、内容を追加し網羅性を高めた。このため第5章までの章立てとした。第3章から第5章に渡り、「ニューロチップ 〜本戦に突入」と題して、ニューロチップの現状と、具体事例、そして最後に動向と今後に関して報告する。
第3章では、「基本回路構成とニューロチップの全景」と題して、2016年前半で量的にも技術的にも激しく変化したニューロチップ(乱戦気味だが)の状況を意識しながら説明する。最初の3.1節、3.2節で動向および基本的な回路構成(積和エンジン)を説明した後に、3.3節でここ1〜2年の間に発表された幾つかのチップを用い全体を俯瞰する。
第4章では「代表的なチップ」と題して、4.1節から4.3節に掛けて全体を3つのカテゴリーに分けて各チップの詳細を説明する。最初に説明する2つのカテゴリーは、畳込み層(CONV層)に重きを置いたチップ(CNN:Convolutional Neural Networkチップ)のカテゴリーと、全結合層(FC層:Fully Connected)に重きを置きさらに学習機能を内蔵したチップ(DNNチップ:DNNの呼称に関しては後述するが本寄稿では「非CNN」と狭義の意味で使用)のカテゴリーである。3つ目のカテゴリーは圧縮技術を搭載したチップ(前2つのカテゴリーと重複して説明するチップあり)のカテゴリーである。
最後の第5章「動向と今後」では、5.1節ではニューロモルフィックチップであるIBMのTrueNorthに関して説明を行う。ただし、本寄稿ではTrueNorthの構成・動作を概説するが、ニューロモルフィックチップとして期待される人間の脳により近い科学的な側面よりも、現在のディープラーニングのもたらす、ある意味単純な性能の側面より比較説明を行う。特に、2016年にかけディープラーニングとの架け橋になる技術の報告があった。その報告にもスポットライトを当て、新しい顔を持ったTrueNorthを圧縮という切り口から解説を試みる。5.2節では、モデルの効率化と圧縮技術の合体によりもたらされる一定レベルのCNNモデルの究極の姿に迫る。そして最後に今後の課題を概説する。
第3章 ニューロチップ〜本戦に突入: 基本回路構成とニューロチップの全景
3.1 現状の把握 〜精度追求から低消費電力とリアルタイム性に焦点がシフト
3.2 回路構成の基本(畳込み層)
3.3 チップ性能一覧と技術的ポジショニング
第4章 ニューロチップ〜本戦に突入:代表的なチップ
4.1 代表的チップ(CNN用チップ)〜並列処理、リユース、コンフィギュラビリティ
4.2 代表的チップ(DNN用チップ)〜DRAM混載、もしくは学習機能〜
4.3 代表的チップ(圧縮技術を用いたチップ)〜疎圧縮、量子化、そしてロスレス
第5章 ニューロチップ〜本戦に突入:動向と今後
5.1 ニューロモルフィックチップ〜回路構成とディープラーニングの視点から見た位置取り
5.2 究極の姿へ(一定のレベルへ)〜シンプルなモデルへの適用とNMTへの展開
5.3 最後に〜今後の動向と課題
3.1 現状の把握〜精度追求から低消費電力とリアルタイム性に焦点がシフト
第2章で紹介したように2016年に入りエッジ系(特にモバイル)への適用をマーケットターゲットとした、低消費電力化・高速化(リアルタイム性)を目指した各種の技術、およびニューロチップの発表が相次いだ(第1章の図2を参照)。まず本節では、詳細の説明に入る前に最新の状況および動向を概説する。
(1) ニューロチップの動向(2016年前半まで)
図14の赤い菱形◆で示された十数チップを本章での詳細説明の対象とした。図14は第1章の図2に新たに2つの公知例を加えた。ひとつは、昨年より今年の初頭にかけ発表された清華大学(Tsinghua University)のAngelEyeチップ(CF型のCNNチップ/FPGA参考資料56:AngelEyeの呼称は学会(FPGA2016)プレゼンテーション資料で使用)で、もう一つはStanford 大学のEIE(Energy Efficient Inference Engine/圧縮エンジン、CAD設計止まりでチップではないが:参考資料46:第2章で既報)である。また可能な範囲でチップのコードネーム(例えばEIEとかEyeriss:参考資料48)を図に添えた。2013〜2015年は少ないが、2016年は8個ほど説明の対象とした。なお、CAD設計止まりのものもこの寄稿ではチップと称した。デジタル回路(コア)はCADにより比較的短時間で検証が可能でかつビジネスを視野に入れないならば、本来チップ化に本質的な意味がない場合が多い。ニューラルネットワークの分野ではその傾向がより顕著である。
なお、以下の製品は詳細説明を割愛した。Snapdragon820/820A (Qualcomm社Zerothプロジェクト、参考資料57、58、59:ニューロモルフィックは使用せず通常のHexagon 680DSP/SIMD VLIWを使用)、Myriad2(Movidious社、参考資料60〜65 VLIW:Fathomと称するUSBスティックを発売、DJIとのビジネス、インテルが買収と変動あり)である。割愛の理由は、従来のDSP、GPUベース寄りの技術を使用していることと、細かい技術内容の入手が難しいからである。同様に図14には載せていないがMobileEye社のEyeQ4、EyeQ5(参考資料66, 67:MPC(Multithreaded Processing Cluster)に特徴有り)も割愛した。なお、余談だが、2016年の8月にIntelに買収された米国Nervana社(参考資料68)の創始者のNaveen Rao氏は、2011年にQualcomm/Zerothに関わり、そのニューロモルフィックによる制御(モータ)関連の研究に携わっていた。その後、Nervanaを創設しCEOに就任した。そして今年の8月にIntelに買収され、現在はIntelのVPとしてAI関連(元Nervanaチーム)を牽引している。かなり激しい。話を戻し、Synopsys社等の技術紹介も割愛した。参考資料69、70を参照願いたい。
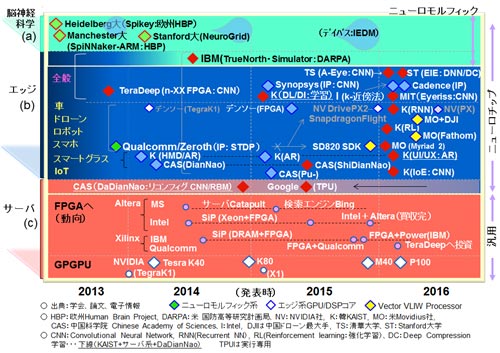
図14 ニューロチップの動向 (2016年7月まで)
(2) 技術の動向
図15を用いて研究(開発)最前線の技術トレンドを説明する。画像認識(Imagenet/ILSVRC)のエラー率を横軸に規模(パラメータ数/消費電力)を縦軸にした。そこに、2012年以降の画像認識(CNN)のモデルと付随した技術の主要なものをプロットした。繰り返しの説明となるが、ベンチマークの舞台となるImagenetはRGBの224x224ピクセルの画像に対して、1000種類のクラス(分類)での識別を行う高精度の画像認識のコンペである。いわゆるハイエンドと言ってもよい。モデルはAlexNetから最近のSqueezeNet(参考資料50:第2章)を使用した。なお、SqueezeNetは第2章で説明したNIN(参考資料26)/GoogLeNet(27)およびResNet(28)の主要素を極めて包括的、啓蒙的(Comprehensive &Instructive)かつ実践的に集約したモデルとの位置づけである。
赤い丸(●)でCF型(畳込み層+全結合層共存型:2.4節を参照)のCNNを、青い四角(■)でC型(後段の全結合層が無しのモデルをC0型、1層有するモデルをC1型と以降呼ぶこととする)を示した。圧縮技術として昨年より大きな成果を出しつつあるDeep Compression(参考資料45:第二章)を今注目の有力技術として加えた。
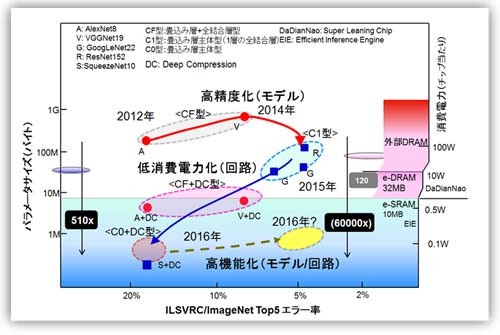
図15 技術トレンド 高精度化→低消費電力化→高機能化へ
この図からトレンドは3つある。
(ア) トレンド1 : CNNの高精度化・・・図の赤矢印線
2012年から2014にかけてモデルの改良が積極的に行われ、2014年にC型のCNNが出て、一層精度が改善された。同時にパラメータ数も一桁程度削減された。
(イ) トレンド2 : CNNの低消費電力化(小型化、高速化)・・・図の青矢印線
2016年に掛けて、低消費電力化(高速化)を目指した圧縮技術が考案・実装され低消費電力化が実現可能となった。Deep Compression /EIEのチーム(Stanford大+UCB+NVIDIA)の圧縮技術がその代表である。モデルの改善と圧縮技術で1〜2年前に対してパラメータ数が数百分の一(510xはSqueezeNetの結果、参考資料50)に減少した。前半のトレンド1はアルゴリズムなりネットワークモデルの改善で、後者のトレンド2は実装技術寄りの改善と見ることもできる(よりLSI実装に近い)。アルゴリズム寄りの研究者から、半導体技術者へと活躍できる人材の場が広がった。また必然だがより製品を意識したトレンドとなって来た。製品を意識して敢えてオリンピック級(1000クラスの識別)の性能を前提としていないのも大きな特徴だ。
パラメータ数の削減は、チップに搭載可能な最大メモリ容量を意識して行われるべきだ。DRAM混載を試みたDaDianNao(参考資料37)は32MB搭載し、またSRAMオンチップのEIE(参考資料46)は10MBを搭載する。その値を各々図に示した。ここで重要な点は、外部メモリのDRAMに対してオンチップ化しSRAMとすることで、アクセスのための消費電力が120分の1になるという点である(参考資料13)。圧縮率510xを考慮すると、単純計算だと数万分の1の消費電力が実現されチップレベルでの実装が可能となる(単純計算だと6万分の1)。事実、かなりの多くのチップで100mA前後の消費電力が実現されてきた(例えば、KAIST/IoEチップは45mA 参考資料71)。なお、同様に高速化(リアルタイム性)も実現される。現実的にサブ100mAが実現可能となった。超高精度を狙わなければ、そもそも曖昧で良い所をきっちりやり過ぎていた(学習はともかく、実行では32ビットもいらない)。本来の姿に戻したと見ることもできる。
(ウ)トレンド3 : 全結合型の小型化(高機能化)・・・図の点線
同時にCF型もしくはF型の全結合主体のモデルに対しても検討がなされた(直感的に全結合型の方が無駄は多いと誰しも感ずる)。RNN(Recurrent Neural Network)への適用、そしてその応用事例も発表された(NMT:Neural Machine Translation/ニューロ機械翻訳、参考資料72、73)。図15に入れ込むのは多少無理があるが、トレンド3として、RNNさらにはより複雑な機能をいれこんだネットワークモデルでの圧縮を含めた回路アーキテクチャ競争に移ったと見ることもできる。
(3) LSI回路アーキテクチャとネットワークモデルとの関係
引き続き、各種のネットワークモデル(アルゴリズム)と回路アーキテクチャとの関係を、図16を用いて説明する。図の黄色い領域がネットワークモデル(アルゴリズム)を示し、下部の青い領域がLSI回路アーキテクチャを示す。本来DNN(Deep Neural Network)はCNNも含む広義の意味で使うべきである。しかし、CNN以外もしくは全結合層主体のネットワークを表すのに使われること(例えばDaDianNao参考資料37、EIE 参考資料46)が多いので、本寄稿では非CNN(狭義のDNN)の意味で使用する。なお、図では併記した。
DNNには基本の多層パーセプトロンMLP(Multilayer perceptron 参考資料75)がある。またMLPの組み合わせにより各種学習モデル・アルゴリズム(機能モデル)を可能とするネットワークモデル(構成モデル)が組み立てられる。それらはRBM(Restricted Boltzmann Machine参考資料76、77)/DBN(Deep Brief Network, 78)、AE(Auto Encoder、79)、さらにはCDBN(Convolutional DBN、80)等である。本寄稿では詳細の説明は割愛する(詳細は上記の参考資料および14を参照)。これらのネットワーク(構成モデル)の上に、機能モデルであるRNNなりRL(Reinforcement Learning:強化学習)が実装される。例えば、「RNN(機能モデル)がCNN(構成モデル)上に実装される」という表現も可能なのだ。なおその場合にはCDBNに習いCRNNと表現されるのかもしれない。なお、CNNは機能モデルと同時に構成モデルとしても使われるので留意が必要だ。
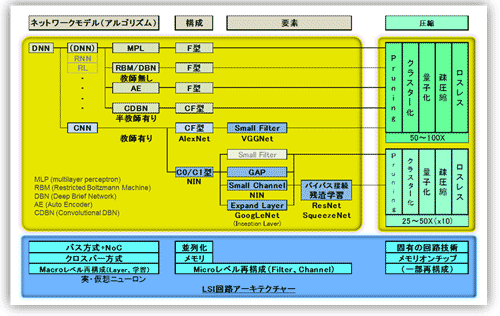
図16 ネットワークモデルとLSI回路アーキテクチャの関係
(DNNとMPL等、狭義の意味で使用しているので注意を要する)
図16のネットワークの“構成”および“要素”は、第2章および前節で説明したのでここでの説明は割愛する。“圧縮技術”に関しては、前章の2.8節ではバイナリ化(Binary Connect、Binarized Neural Network等)を含めて紹介したが、図16では今年に入り実装も含めて進捗の度合いの大きいDeep Compressionを中心に記載した。詳細は4.3節で説明する。
図16の下部にLSI回路アーキテクチャの技術項目を並べた。ネットワークの階層(モデル、構成、要素、圧縮)に習い分けた。また技術項目を列記すると以下の(1)〜(6)となる。
(1) バス方式とクロスバー方式(実・仮想ニューロン)
(2) NoC
(3) 再構成可能性 (Reconfigurability)
(ア) マクロレベル Layer/学習方法
(イ) ミクロレベル Filter/チャネル数等
(4) 並列性(特にCNN)
-再構築可能性とも強く関連する
(5) メモリオンチップ
-全結合層を含むF型/CF型(C1型)で特に重要
(6) 圧縮技術
(ア) 固有回路技術・・・(特にF型/CF型(C1型)で重要
(イ) 固有回路不要技術
が回路アーキテクチャの技術項目(課題)である。
(4) 畳込み層と全結合層
回路アーキテクチャおよびチップを理解するために、畳込み層と全結合層の実装上の違いをおさらいする。その差異を表5に記載した。基本式はかなり違う(詳細は次節3.2節で述べる)。畳込み層は計算主体(computational-centric)、全結合層はメモリ主体(memory-centric)の特性を持つ。前者は、重みを平均100〜1000回(初段の畳込み層の出力の次元数でほぼネット平均リユース回数が決まる)リユースすることから計算主体となる。その分、リユース効率を上げるために並列処理手法に工夫が必要である。逆に全結合層は演算ごとに新しい重み(メモリアクセス)が必要となる。また圧縮効果は特徴マップの局所的領域で絞って演算をする畳込み層では相対的に小さい。さらにRNN、RLは全結合層で構成される。
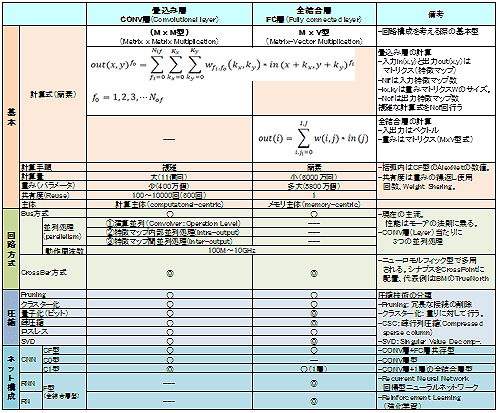
表5 畳込み層と全結合層との比較表
(続く)
参考資料は、第3章の最後にまとめて掲載する。
編集注)百瀬氏の現在の肩書は、北海道大学 大学院情報科学研究科 学術研究員である。

 インサイダーズ
インサイダーズ インサイダーズ
インサイダーズ インサイダーズ
インサイダーズ インサイダーズ
インサイダーズ インサイダーズ
インサイダーズ セミコンポータル編集長
セミコンポータル編集長 半導体関連市場の動向
半導体関連市場の動向 技術コンテンツ
技術コンテンツ 経営・戦略ビジョン
経営・戦略ビジョン トピックス解析コラム
トピックス解析コラム